일단, 이번 글과 관련된 나의 고뇌는 아래와 같다.
https://eglife.tistory.com/366
SQL2NL 모델 추가 실험(VectorDB, Embedding)[4]
https://eglife.tistory.com/364 SQL2NL 모델 추가 실험(VectorDB, Embedding)[3]https://eglife.tistory.com/363 SQL2NL 모델 추가 실험(VectorDB, Embedding)[2]https://eglife.tistory.com/362 SQL2NL 모델 추가 실험(VectorDB, Embedding)[1]https://eg
eglife.tistory.com
https://eglife.tistory.com/365
[Review]Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQL
https://arxiv.org/abs/2501.12372 Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQLLarge Language Models (LLMs) have demonstrated impressive capabilities across a range of natural language processing tasks. In particular, improvemen
eglife.tistory.com
항상 지속적으로 문제가 되고 있는 NL에 대한 정확도 평가 방법..
결론은, SQL2NL의 결과물인 NL에 대해선 평가수치를 내리는 것이 무의미하니,
해당 Model에 대해선 모델 이용 전에, NL을 1차적으로 BERT/BLEU Score로 검증해보고 그리고 Human based evaluation으로 추가 검증한다.
그 후, NL2SQL에 이용하는 Logic flow를 가져보기.
전체적인 골자는 아래와 같다.
-> 적어도 BIRD BenchMark에선 잘 동작하는(특정 Domain Specific한) SQL2NL 모델을 STEP 1에서 만든다.
-> STEP 1에서 해당 모델에 대해서 검증할땐 BERT,BLEU도 좋은데 걍 Human 평가까지 포함시켜서 BIRD 에서 위 기법이 잘 동작하는 것을 보여준다. => 이게 잘 되면, 어떤 Domain이든 이 기법을 이용해서 SQL2NL 모델을 만들 수 있다는 일반화로 넘어갈 수 있다.
-> 이제 STEP2로 넘어 간다.
-> 전반적인 NL2SQL 모델이 아닌, 특정 Domain Specific(Like BIRD)한 NL2SQL 모델이 Target이다.
| ㄱ. BenchMark로서 SQL2NL 이용 NL2SQL ->SQL ouput 결과 A 저장 -> SQL2NL(여기서 나온 점수로 평가? 의미 없음 나올 수 있는 점수가 BLEU/BERT 이런 참고용일 뿐. 그냥 SQL2NL이 절대적인 BenchMark라고 가정을 찍어버려야 한다.) -> NL2SQL -> Output 결과 B를 결과 A와 비교해서 같으면 OK 다르면 NO ㄴ. NL2SQL 모델 Finetuning / 강화학습 등등에 사용.. 이건 내가 논문으로 쓸 수 있을지 모르겠다. 강화학습개념도 잘 없고(물론 LLM과 함께하면 비벼지겠지만..) 무엇보다 실익이 있을지 의문이다..ㅎ 그래도 Logic을 생각해보자면, NL A -> NL2SQL -> SQL2NL -> NL B -> NL A와 NL B가 맥락적으로 같아질 수 있도록 Finetuning or 강화학습 시작!(LLM한테 시켜야 겠지ㅎㅎ?) 이렇게 해서 만들어진 NL2SQL모델이 Naive Model보다 성능이 좋다고 여기면 된다.. |
위 ㄱ에 대해서 유효성을 보여주려면 어떤 실험을 진행해야 할까? 기존 코드를 잘 만지면 ㄱ을 이용하는 실험은 간단히 진행해볼 수 있을 거 같은데,, 그 효과를 어떻게 보여줄까?
(특정 Model이 맞췄던 문제 / 못 맞췄던 문제를 나누어서 나의 SQL2NL Model을 Benchmark로 활용했을때도 결과가 맞춤 or 못 맞춤으로 나오는지를 보면 되지 않을까?? 근데 아무래도 다른 NL을 input으로 넣는거라 결과가 같을 것이라고 예상하진 않는다..ㅠ)
ㄴ의 경우, 급하게 강화학습/파인튜닝 내용을 대충 찾아보고 NL2SQL Model을 하나 만들 수 있지 않을까 하는 생각이 든다.
일단 ㄴ은 차치하고, ㄱ부터 Develop 해보자.
내 SQL2NL Model의 Novelty는 SQL의 구조적 특성을 Parsing을 통해 이용한다는 것이다. 이 점이 기존 NL2SQL Task에 내 연구를 바로 넣을 수 없는 까닭이다.
Input이 NL이면 그와 유사한 Examplar는 그냥 Text embedding을 통해서만 불러올 수 있기 때문이다.
하지만, Input이 SQL인 SQL2NL Task에선 SQL의 구조적 특성을 통해 유사도가 높은 Examplar를 최대한 가깝게 가져올 수 있다.
즉, Input이 NL일때보다 SQL일때 Similarity가 더 높은 Examplar 추출이 가능하다고 가정!
그래서 위 내용을 바탕으로 NL2SQL Model 적절한 거 아무거나 가져와서 얘에 대한 Evaluation을 진행할 수 있다.
| ※ 갑자기 생각난 문제는, NL2SQL Model이 SQL을 Infer할 때 매번 같은 결과를 낼까? 뭔가 아닐거 같다.. a 라는 NL을 b라는 SQL로 잘 변환했다가도, 이게 LLM을 이용하는 Task이다보니 어떨 땐 같은 a라는 값에 대해서 b' 라는 다른 SQL을 변환할 수도 있다고 생각한다. -> 써치해보니 그것은 보장되지 않는다고 한다. LLM GPU의 Sampling기반 Decoding 과정에서 Sampling 경로가 달라질 수 있어서 같은 조건 + 같은 Input이어도 다른 Ouput이 나올 수 있다고 한다. 억지로 Deterministic mode를 쓰면 된다고 하지만, 일반적인 LLM사용 환경에선 그렇게 Setting하긴 어렵다. 즉, 다시 말해 NL2SQL의 정확도를 측정할 때 한 Flow에서 측정해야 한다. |
여기서 한 Flow란 무엇일고..
일단 내가 NL2SQL Model A와(시중에 떠도는거 적당한 거 암거나) SQL2NL Model B를(Ours!!) 보유하고 있다고 가정하자.
이 때, BIRD Dataset을 쓰는데 최대한 정제된(Refined) Dataset을 쓰자. BIRD 자체에도 Error가 약 25% 있다는 것은 학계의 정설이다.

이게 반대로, Result 1 / Result 2 비교 정확도가 95%정도만 나와도 Error 5%에 대해선, 위 박스에서 언급했던
LLM의 비일관성(?)을 Error원인으로 적을 수도 있다.. 부디!! 내일 실험 한 번 돌려보고 정확도를 측정해보기.
슬 실험을 돌려야 한다 예엠병!
시간을 좀 보내고.. 조깅을 뛰면서 생각한건데, 위 Logic대로 잘 동작했다고 치자. 그럼 이 Framework의 효용성이 뭐냐? 무조건 각광받는 산업인 NL2SQL이 틀렸는지 맞았는지는 모범답안만 있다면 Result1만 봐도 알 수 있는거고 저렇게 Result1, Result2를 비교해서.. So.. What? 이라는 거다. BIRD / SPIDER 같은 Benchmark를 대체할 수 있는 근거가 없다..(어차피 Test data는 공개되지 않으니까)
되려, 저 그림은 SQL2NL Model의 정확도를 판단하는 지표로 쓰일 수는 있겠다라고 생각이 든다.
Result1 과 Result2가 일치하는 Case가 많을수록 Model B가 SQL을 NL로 적절히 바꿨다고 판단해볼 수 있다.
물론, LLM을 거치는만큼 일종의 Uncertainty가 올라가긴하지만, 이 정도는 어쩔 수 없다고 본다.
이제 SQL2NL Model은 BERTRecall , BLEU, (BART 제외), Human Based, NL2SQL Model을 이용한 평가로 그 정확도를 나타내볼 수가 있다.

근데 문제는,, 이건 Whole Framework에서 내가 그동안 ' SQL2NL Model은 무조건 정확하다고 가정하자! ' 의 영역이다. 주요 Point는 어떻게든 SQL2NL Model을 NL2SQL과 엮어야 Merit가 있는데...
나는 아무리 봐도 ' 모델학습 ' 에서 이것을 활용하는 것만이 떠오른다.
| ㄴ. NL2SQL 모델 Finetuning / 강화학습 등등에 사용.. 이건 내가 논문으로 쓸 수 있을지 모르겠다. 강화학습개념도 잘 없고(물론 LLM과 함께하면 비벼지겠지만..) 무엇보다 실익이 있을지 의문이다..ㅎ 그래도 Logic을 생각해보자면, NL A -> NL2SQL -> SQL2NL -> NL B -> NL A와 NL B가 맥락적으로 같아질 수 있도록 Finetuning or 강화학습 시작!(LLM한테 시켜야 겠지ㅎㅎ?) 이렇게 해서 만들어진 NL2SQL모델이 Naive Model보다 성능이 좋다고 여기면 된다.. |
위 강화학습은 너무 Rough하고, 조깅을 뛰면서 생각해본건
우리가 공부하듯이 모델도 학습시키는 것이다. 시험공부를 할 때, 맞은 문제는 넘어가고 틀린 문제에 대해선 해당 유형과 비슷한 문제를 많이 풀어본다. 이래야 틀린 유형에 대한 학습이 올라가는 것이 당연하다고 생각하기 때문이다.
그래서 생각한 것이, NL2SQL 모델을 Finetuning할 때 틀린 Data pair에 대해서 Gold SQL + SQL2NL 모델을 가지고 Gold SQL과 유사한 뜻을 가진 NL을 N개 만들어 이 Pair를 추가로 학습시키는 것이다.
근데,, 이 때 문제는
| 1. Train Data를 추가하면 일반적으로 전체 재훈련이 필요하다. -> Model이 데이터 분포 등도 반영시켜서 Train하기 때문 Solution? -> Incremental learning : 새로운 데이터만 추가로 학습하는 기법(Catastrophic forgetting 문제 해결 必) LoRA/PEFT 방식(KTS 교수님 전문분야), Continual Learning, Data Mixing 등의 기법을 사용할 수 있다. 2. Model 틀린 문제에 대해서 유사한 데이터 Sampling / Augmentation을 이용해 학습강화하는 연구는 이미 되고 있다. -> 찾아보면 됨 |
내 평소 연구랑 결이 확 달라진다. LLM Training / Deep Learning의 영역으로 넘어가는 느낌..
그래도 졸업하기 전에 LLM Finetuning과 Hugging Face이용을 한 번은 해보고 싶었는데 오히려 잘 됐나? 싶기도 하고..ㅎ
이건 KDBC처럼 모 학회가 있을 때 따로 체크해봐야 겠다.
다시 본론으로,
그러면 지금 SQL2NL Model을 다시 검증하는 것을 필두로 함 해보자.
BIRD Data를 좀 더 가공 및 Embedding 최적화하며 코딩을 좀 더 진행해보자.
현재 기준, 아래와 같다.
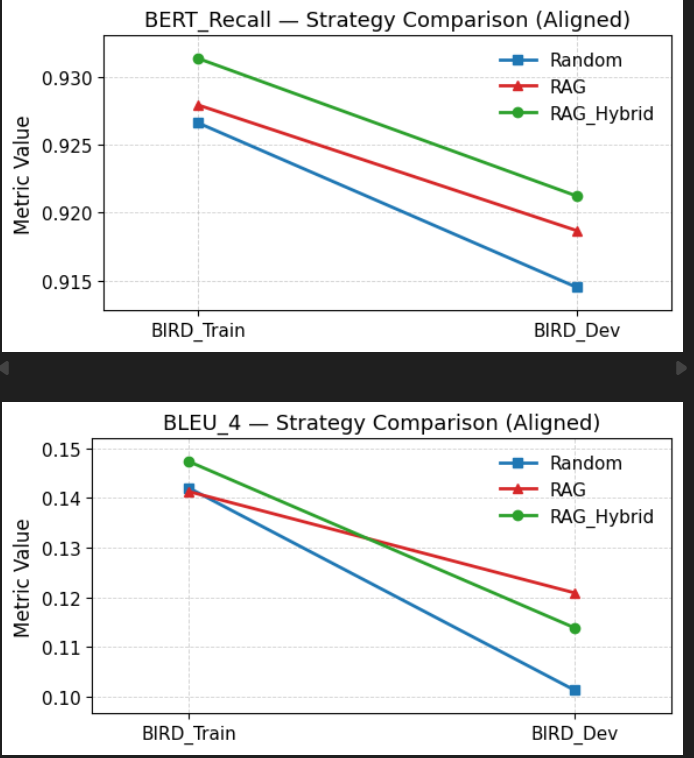
일차 목표는,
BIRD_Train, BIRD_Dev, 그리고 내가 Refine한 Dataset에서 모두 RAG_Hybrid가 가장 높고, 그다음 RAG 그 다음 Random 순인 Graph를 얻는 것.
이차 목표는,
Human Based Evaluation 과 NL2SQL Model을 이용한 Evaluation도 진행하는 것.
최종 목표는,
위에서 개발한 SQL2NL Model을 NL2SQL Model Finetuning에 활용해서 이득을 보는 것이다.

'Data Science > Research' 카테고리의 다른 글
| SQL2NL 모델을 NL2SQL에 적용시켜보기[3 - 잠정 stop] (0) | 2025.09.25 |
|---|---|
| SQL2NL 모델을 NL2SQL에 적용시켜보기[2] (0) | 2025.09.18 |
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[4] (0) | 2025.09.04 |
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[3] (2) | 2025.08.18 |
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[2] (6) | 2025.08.11 |