https://eglife.tistory.com/364
SQL2NL 모델 추가 실험(VectorDB, Embedding)[3]
https://eglife.tistory.com/363 SQL2NL 모델 추가 실험(VectorDB, Embedding)[2]https://eglife.tistory.com/362 SQL2NL 모델 추가 실험(VectorDB, Embedding)[1]https://eglife.tistory.com/361 SQL2NL 모델 실험진행(2)https://eglife.tistory.com/360 S
eglife.tistory.com
Data는 웬만큼 뽑았다.
이제 실험한 Data에서 유의미한 내용을 뽑고 잘 시각화하는 것이 중요할듯.
BAR / Line Graph로 각 Prompt Case (Random, RAG, RAG + SQLglot) 별로 Evaluation 결과 차이가 잘 보이게 세팅해야한다.
그렇게 세팅하고 나서,
Human based 평가 + NL2SQL Model을 써서 평가 하는 항목을 넣으면 되겠다.
Evaluation Matrix만 추가하는 것이라서 Graph/Chart 분석 Code만 제대로 닦아 놓으면 이것들 추가해서 분석하는 것은 일도 아니다.
근데 이 평가방식들을 왜 추가할까?
일단 지금까지는 SQL-to-NL(Natural Language) 의 Output Semantic 정확도를 측정하기 위해서 BLEU-4 / BERT Recall / BART Score을 사용했다. 이것들의 특징을 다시 한 번 Review하자면 다음과 같다.
1) BLEU‑4 (n‑gram 정밀도 + 길이 패널티)
2) BERTScore (Recall 선택)
3) BARTScore (조건부 생성 확률 기반)
|
좀 말이 어려워서 GPT5에게 비전공자도 잘 이해할 수 있게 쉽게 내용설명을 해달라고 하였다.
1) BLEU-4👉 문장 속 단어 조각(n-gram)이 얼마나 똑같이 들어맞는지 보는 지표
2) BERTScore (특히 Recall 기준)👉 단어가 다르게 써도 의미가 같으면 높은 점수를 주는 지표
3) BARTScore👉 언어 모델(BART)이 ‘이 문장이 자연스러운가?’를 확률로 계산한 점수
정리: 세 지표의 차이
|
BERTScore는 BERT모델을 통해, BARTScore는 BART라는 모델을 통해서 문장의 매끄러운 정도를 평가하고, 이 때문에 Semantic 측면에서 비교해보자면 BERT나 BART를 쓰는 것이 맞다. 사실 BLEU_4는 받아쓰기 맹키로 너무 투박한 비교방법이긴 하다.
BERT(Encoder Only) / BART(Encoder+Decoder)는 각각 Google / Meta에서 만든 사전학습(Pre-trained) 언어모델이다.
BERTScore의 경우 '정답'과 '예측' 문장을 BERT Embedding 시켜서 Vector Similarity를 계산한다.
요건 이해하기가 쉽다.
반면 BART의 경우 Train할 때 원래 문장을 일부러 망가뜨리고 다시 복원하는 법을 배운다. 망가뜨린다는 것은, 단어 몇 개를 가리거나, 문장의 순서를 섞는 것이다.


즉, 정답 문장을 만들기 위해서 예측 문장이 얼마나 많은 수고를 해야 하는지를 판단하는 것이다. 품이 많이 든다면 Score는 낮고, 품이 적게 든다면 Score는 높다.
GPT5 dev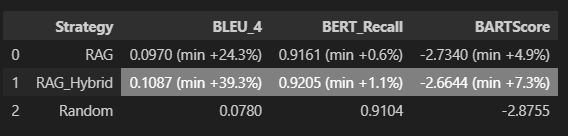 |
GPT5 train |
GPT5 mini dev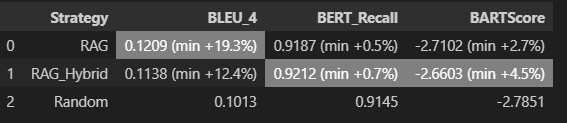 |
GPT5 mini train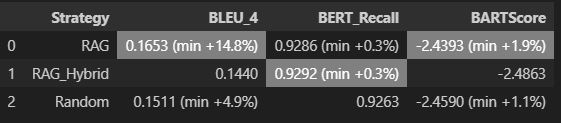 |
GPT5 nano dev |
GPT5 nano train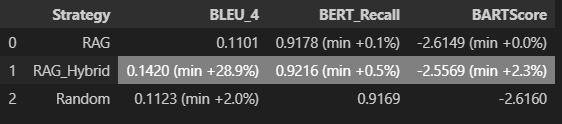 |
일단 마사지 하기 전, 데이터는 위와 같은데 dev / train set 모두 nano 모델에서 RAG Hybrid가 가장 성능이 좋다. 근데 생각보다 드라마틱한 성능향상은 없어서 좀 머쓱하긴 하다..
추가로 생각해보면,, BARTScore는 빼는게 낫지 싶다. NL의 유사도를 보는데 문장의 자연스러움?은 굳이 왜 보는가 하는 의구심이 들기 때문이다.
1. 두 문장이 단어겹치는게 많다면 유사하다 -> 합당한 논리 -> BLEU-4 Score
2. 두 문장의 BERT Embedding 후 유사도가 높다 -> 합당한 논리 -> BERTScore Recall
위 2개만 가져가고, 나머지 평가지표로 Text2SQL 모델을 합쳐서(?) 평가를 진행하고자 한다.
+ Human Based 평가까지! 이거는 연구실 사람들에게 Survey 방식으로 부탁을 좀 해야겠다.
이게 잘만 먹히면 진짜 좋은 Text2SQL 모델을 하나 만들 수 있는 것이다..!
근데 어떻게 잘 만들 수 있나?
기존에 NL2SQL은, Gold NL 넣고 Predicted SQL과 Gold SQL의 쿼리 실행결과를 비교해서 Execution Accuracy (EX) 를 측정한다.
이거 잘 할려고 NL Prompt에 Schema linking, Few-shot 등등 지금 SQL2NL에 적용시킨 모든 기법을 포함한 각종 기교를 부린다.
모델 Fine tuning도 물론 시키겠지..!
NL2SQL Frame work는 크게 두 가지 In-Context-Learning : Prompt Engineering , Model Finetuning 로 나뉜다.
위 Frame work에서 내 SQL2NL을 어디다가 사용할까...?
요즘엔 이 영역이 강화학습으로 넘어가서 Model Finetuning에 집중된다고 하는데(Prompt는 거의 포화상태 ;; ) 이 기법을 Model Tuning에 사용할 수 있으련지..
어쨌든 GPT랑 대화하며 내 것을 text-to-sql 파인튜닝에 쓸 수 있는 방안 마련중...
확실히 RAG이용 Few-shot은 괜찮을 듯 허다. Few-shot의 퀄리티가 아무래도 높으니..
BIRD제출할때 FAISS DB도 제출할 수 있나...? FAISS DB를 open Cloud에 올리고 그걸 코드에 넣어도 될듯?
메모장 내용이 좀 중구난방이라 새로운 글을 다시 파야겠다.
골자는, SQL2NL Model을 (미숙하지만) 잘 만들었다고 치고, 이걸 NL2SQL Model에 어떻게 적용시키냐이다..
- To Be Continued -

'Data Science > Research' 카테고리의 다른 글
| SQL2NL 모델을 NL2SQL에 적용시켜보기[2] (0) | 2025.09.18 |
|---|---|
| SQL2NL 모델을 NL2SQL에 적용시켜보기[1] (0) | 2025.09.11 |
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[3] (2) | 2025.08.18 |
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[2] (6) | 2025.08.11 |
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[1] (4) | 2025.08.04 |