https://eglife.tistory.com/362
SQL2NL 모델 추가 실험(VectorDB, Embedding)[1]
https://eglife.tistory.com/361 SQL2NL 모델 실험진행(2)https://eglife.tistory.com/360 SQL2NL 모델 실험진행https://eglife.tistory.com/359 SQL2NL 모델 개선방안에 대한 검토 - Prompt & RAGhttps://eglife.tistory.com/358 연구주제 고찰
eglife.tistory.com
이전 시간에, 대강 SQL에 적합한 Feature를 통해서 해당 항목 기준으로 Embedding 하는 것까지 완료 했다.
근데 오늘 Embedding Model에 대한 세미나를 듣다보니 이렇게 접근하는 게 맞나 싶다.. 😥
Embedding 모델 자체도 Train을 통해서 만들어지는 것이고 Embedded Number, 가령 [0, 0.1, 3.999, 0.1..] 등의 각 차원을 대표하는 Number가 실상은 크게 의미가 없다는 것이다.
그리고 이게 Feature가 전부 Binary가 아니고 일부 Numbery면 Chroma 내부적으로 거리 계산을 할 때, Feature의 값을 크게 계산한다. 즉, 좀 더 결과에 영향력이 커지는 것

그래서 일단, 모든 임베딩을 0, 1 Feature로 하였다.
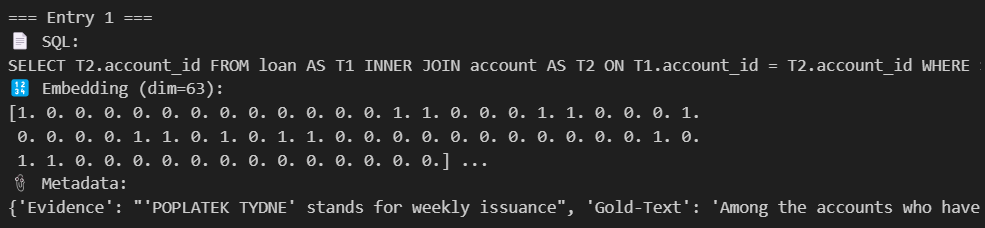
그런데 이렇게 하니까,
Cosine 유사도 계산 결과 값이 0이거나 1인 경우가 많다.

이러면 정확하게 유사도를 계산했다고 말하기가 어려운 것 아닌가..?
흠.. 그래서 다시 Binary가 아닌 Integer vector embedding도 허용해보기로 한다.
다시 괴상하게 벡터임베딩을 마치고,

TOP-5를 돌려본다.
그래도 여전히 유사도가 0,1 이렇게 극단적인 값들이 많다.

해결방법은 찾아보자.
1. Chroma 내부에서 백터 정규화를 L2거리로 탐색
( 단점: L2는 크기 차이를 직접 반영하므로, scale normalization이 없으면 편향 가능 )
collection = client.get_or_create_collection(
name="sql_nl_gold_l2",
metadata={"hnsw:space": "l2"}, # 👈 L2 거리 기반 HNSW 설정
embedding_function=None
)
흠,, 역시 scale normalization이 없어서 그런가 값이 이상하게 찍힌다.
0, 1, 0 ,1 만 있다가 195, 150 이렇게 큰 숫자가 등장해서 계산이 꼬인 것으로 보인다.
그리하여 Vector Embedding / Retrieve를 하는 과정에서 Entity 별로 Query Vector Normalize를 진행해주었다.
# Embedding
vec = extract_sql_features(sql)
norm = np.linalg.norm(vec)
embedding = (vec / norm if norm > 0 else vec).tolist() # 👈 L2 거리 기반 정규화
# Retrieve
前 :
query_vector = extract_sql_features(input_sql).tolist()
後 :
vec = extract_sql_features(input_sql)
norm = np.linalg.norm(vec)
query_vector = (vec / norm if norm > 0 else vec).tolist()
그러나.. 그래도 결과가 너무 High에 몰려있다. 다만 유사도가 0으로 나오는 현상은 보이지 않게 되었다.
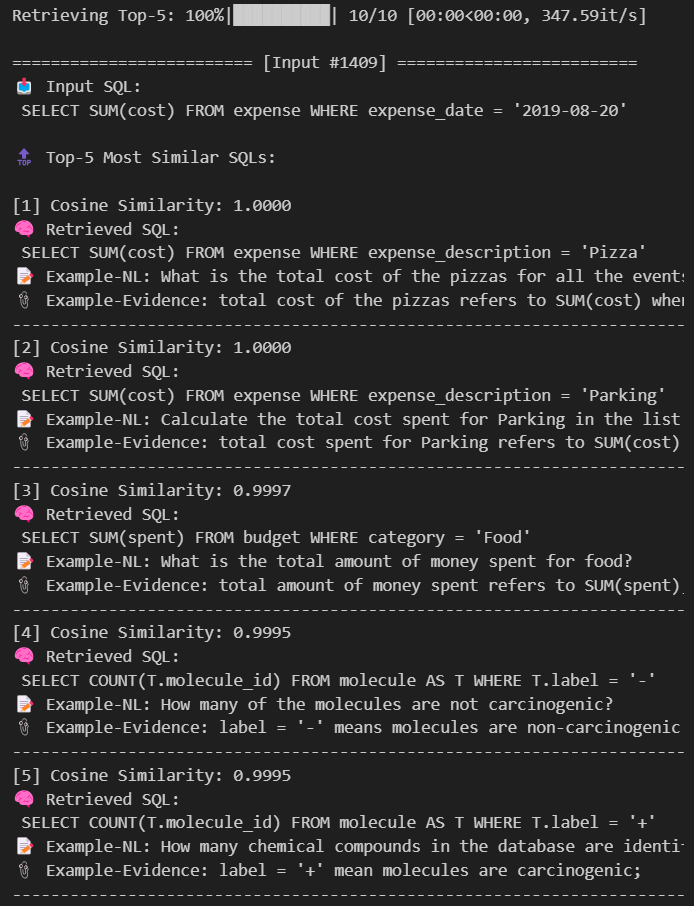
일단 Normalize할 때 정수가 너무 큰 놈 위주로 가중치가 커질 거 같아서 큰 놈(len_n_char)은 제거했는데,
나머지 정수들도 손을 좀 봐주긴 해야할 거 같다..
근데 어떤 기준으로 그놈들을 제거하는지가 문제 ㅠ
2. 백터 차원 수를 늘리기

보통 2의 승수 단위로 차원을 늘리길래, 다시 Feature는 Binary로 바꾸고 해당 Binary feature들의 조합을 통해서 총 256차원의 Embedding을 진행하기로 하였다( ex) Groupby + Orderby 가 같이 쓰였는지 등 )
조금의 Similarity 계산 개선점이라도 생기길 바라며 실험진행
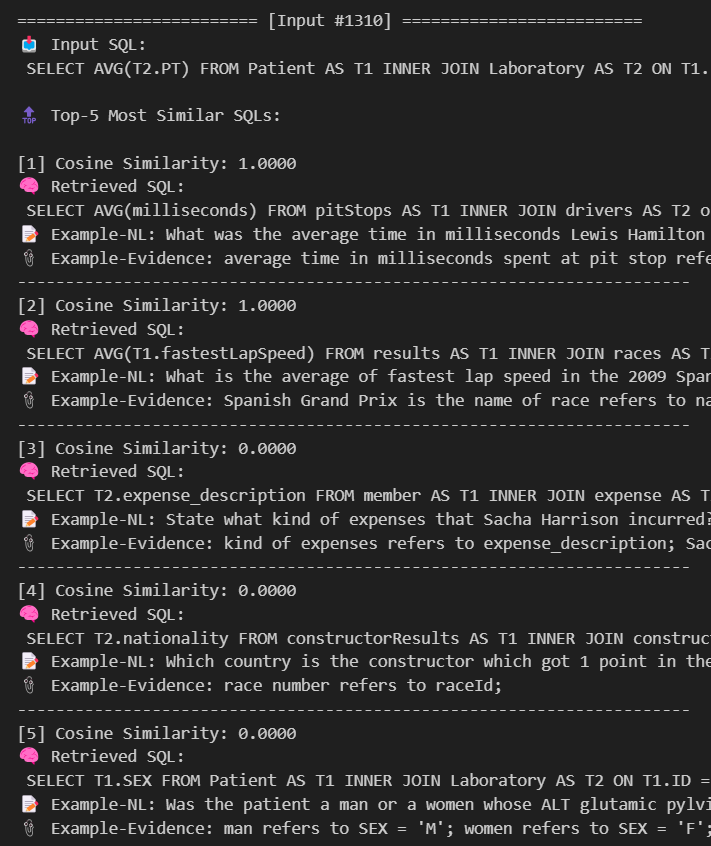
이렇게 하니까 유사도가 0,-1,1 만 나온다.. Binary 형태의 feature를 여러개 제시해서 Dimension 늘리는 건 효과가 없는 것으로..ㅠ
3. TOP-K를 뽑고 거기서 SQLGLot diff function기반으로(이건 K-DS논문으로 효과성 증명 完) 다시 TOP-K를 뽑는 Hybrid 방안
결국 이 방안이 제일 좋긴하다.. 근데, VectorDB에서 Top-K를 뽑긴 뽑아야 SQLGlot diff으로 추가 filter를 거니까 VectorDB에서 후보군을 뽑는 것은 유지하는 것이 마땅하다.
다시 한 번 정리하자면, 후보군 SQLGlot diff으로 추리는 것은 이미 K-DS에서 괜찮다고 증명이 되었다. 심지어 그 때는 Schema Linking도 안 했었는데 이번에 그것까지 추가하면 더 좋긴 할 듯.
Binary Feature만 쓸 것이기 때문에, Cosine Similarity가 아닌 Jaccard Similarity를 쓰기로 하고 이 때문에 VectorDB로 Chroma가 아닌 FAISS를 쓰기로 정정(Chroma는 JACCARD 지원하지 않는다.)


옘병;;
근데 또 찾아보니까 FAISS는 VectorDB Data저장할 때 Metadata는 따로 Linking 해줘야 한다고 한다..
이게 Data Retrieve후에 Gold NL + Evidence (Metadata) 를 같이 Prompt에 줘야 해서 같이 관리해줘야 하는데.. 왜 둘이 합쳐진 Case는 없는 것인가 ㅠㅠ

일단, Jaccard + Metadata 따로 관리하는 방안으로 문제해결 하긴 했다.
Jaccard Similarity 계산도 너무 Sparse하지 않게 적절히 잘 나온다.
이 방법을 기준으로 Develope 하면 될 거 같다.

But..!
아즉, FAISS의 Search기능을 쓰지 않았다..
그냥 for문으로 Data Retrieve하고 있었음 ㅎ;; 이건 RAG의 기능을 완전히 사용한 것이 아니다. RAG의 생명은 Speed인디!
for i, row in enumerate(test_data[:3]): # test 데이터 확인조절
input_sql = row["SQL"]
input_id = row.get("question_id", f"test_{i}")
input_vec = extract_sql_binary_features(input_sql)
# pad to 64D
if len(input_vec) % 8 != 0:
pad_len = 8 - (len(input_vec) % 8)
input_vec = np.concatenate([input_vec, np.zeros(pad_len, dtype=np.uint8)])
# Jaccard 계산
top_scores = []
for j, db_vec in enumerate(binary_matrix):
score = jaccard_score(input_vec, db_vec, average="binary", zero_division=0)
top_scores.append((score, j, sql_list[j], meta_list[j]))
# Top-5 선택
top_scores.sort(reverse=True)
results.append({
"input_id": input_id,
"input_sql": input_sql,
"top5": top_scores[:5] # Top 개수 조절
})
확실히, RAG Search기능을 쓰니까 결과가 바로 나온다.
for loop는 데이터 1400~1500개 기준 4~5초 정도 걸리는데, RAG Search는 진짜 0초대에 결과가 나와버린다.
괜히 RAG~ RAG~ 하는 게 아닌가보다.
FAISS에서 Similarity계산은 크게 Hamming Distance or Jaccard를 써볼까 하는데 각각의 차이는 아래와 같다.
1. Hamming Distance정의
2. Jaccard Similarity정의
|
Binary Feature의 경우 사실 Hamming이나 Jaccard 모두 비슷할 거 같은데, 그래도 각종 연구논문에 Jaccard가 많이 쓰이니까 Jaccard 최적화에 나섰다.
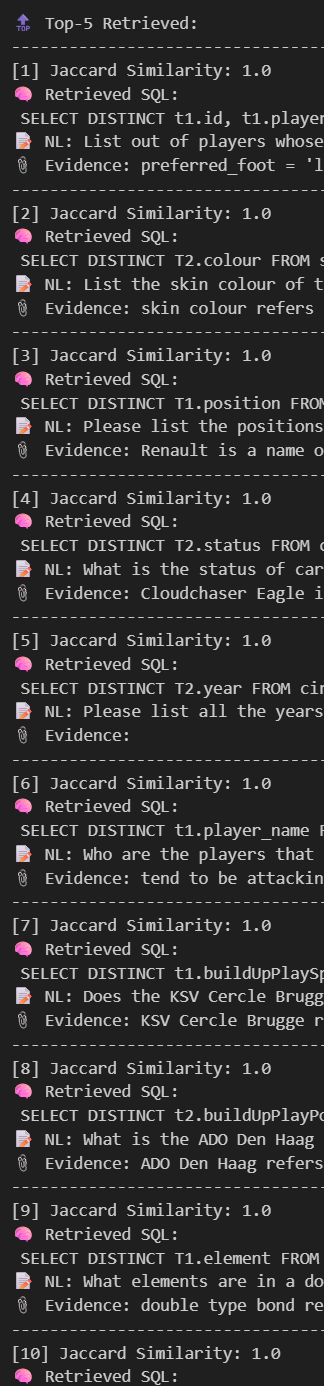
근데 문제는, 임베딩이 Binary로 너무 Rough해서 그런가, 이렇게 모든 경우에 1.0으로 떨어져서 Top-K 추출이 무의미한 케이스가 더러 있다..
해결법으론 Score에 Weight를 주거나, Embedding을 좀 더 조밀하게 하는 것인데... Score에 Weight를 주는 건 Model train의 영역이라 일단 SKIP하고 Embedding부분에 초점을 맞춰보자.
import re
import json
import numpy as np
from tqdm import tqdm
from sqlglot import parse_one, exp
from sklearn.metrics import jaccard_score
import faiss
import pickle
import uuid
# ───────────────────────────────────────────────
# 1. Binary Feature Extractor (40D binary)
# ───────────────────────────────────────────────
# ✅ FAISS 용으로 64차원 (8의 배수)으로 정리한 binary feature 목록
BINARY_FEATURES = [
# Structure
"is_select", "has_cte", "has_subquery", "has_case",
"has_distinct", "has_placeholder", "has_between_dates", "has_union",
# SELECT
"has_star", "has_star_except", "has_star_replace", "has_alias",
# Aggregation
"has_sum", "has_avg", "has_count", "has_min", "has_max", "has_group_by", "has_having",
# WHERE
"has_where", "has_between", "has_in", "has_like", "has_and", "has_or",
"has_exists", "has_is_null", "has_is_not_null",
# JOIN
"has_join", "has_inner_join", "has_left_join", "has_right_join", "has_full_join",
"has_cross_join", "has_semi_join", "has_anti_join",
# ORDER / LIMIT
"has_order_by", "has_order_asc", "has_order_desc", "has_limit",
# Function Types
"has_scalar_func", "has_date_func", "has_string_func",
"has_concat", "has_cast", "has_coalesce", "has_json_extract",
# Others
"has_interval", "has_array_construct", "has_unnest",
# Extended CASE detection
"has_case_when", "has_case_else_guess",
# WINDOW functions
"has_rank", "has_row_number",
# Expression types
"has_eq", "has_neq", "has_gt_lt", "has_arith_expr"
]
# ───────────────────────────────────────────────
# SQLGlot 사용 용 정정 함수 sannitize_sql
def sanitize_sql(sql: str) -> str:
"""
백틱으로 감싸진 식별자 정규화 + 일부 함수 정규화.
- `user-id` → user_id
- `Name` → Name
- DATETIME() → NOW()
"""
def fix_identifier(match):
identifier = match.group(1)
# 특수문자 제거 및 snake_case 변환
return re.sub(r"[^\w]", "_", identifier)
# 1️⃣ 백틱으로 감싼 식별자 처리 → snake_case로 치환
sql = re.sub(r"`([^`]+)`", fix_identifier, sql)
# 2️⃣ DATETIME() → NOW() 변환
sql = re.sub(r"\bDATETIME\s*\(\s*\)", "NOW()", sql, flags=re.IGNORECASE)
return sql
FEATURE_INDEX = {k: i for i, k in enumerate(BINARY_FEATURES)}
def extract_sql_binary_features(sql: str) -> np.ndarray:
vec = np.zeros(len(BINARY_FEATURES), dtype=np.uint8)
sql = sanitize_sql(sql) # Sanitize 추가
try:
tree = parse_one(sql)
except Exception:
return vec
def mark(key):
if key in FEATURE_INDEX:
vec[FEATURE_INDEX[key]] = 1
# ── Base clauses
if isinstance(tree, exp.Select): mark("is_select")
if tree.find(exp.With): mark("has_cte")
if tree.find(exp.Union): mark("has_union")
if tree.find(exp.Case): mark("has_case")
if tree.args.get("distinct"): mark("has_distinct")
if re.search(r":\w+|\?\d*", sql): mark("has_placeholder")
if any(isinstance(n, exp.Subquery) for n in tree.find_all(exp.Subquery)): mark("has_subquery")
# ── SELECT
select_exprs = tree.expressions or []
for sel in select_exprs:
if isinstance(sel, exp.Star): mark("has_star")
if isinstance(sel, exp.Star) and sel.args.get("except"): mark("has_star_except")
if isinstance(sel, exp.Star) and sel.args.get("replace"): mark("has_star_replace")
if sel.alias_or_name: mark("has_alias")
# ── Aggregation
for agg in [exp.Sum, exp.Avg, exp.Count, exp.Min, exp.Max]:
if tree.find(agg): mark(f"has_{agg.__name__.lower()}")
if tree.find(exp.Group): mark("has_group_by")
if tree.find(exp.Having): mark("has_having")
# ── WHERE
where = tree.find(exp.Where)
if where:
mark("has_where")
if where.find(exp.Between): mark("has_between")
if any(re.search(r"\d{4}", str(l.this)) for l in where.find_all(exp.Literal)):
mark("has_between_dates")
if where.find(exp.In): mark("has_in")
if where.find(exp.Like): mark("has_like")
if where.find(exp.And): mark("has_and")
if where.find(exp.Or): mark("has_or")
if where.find(exp.Exists): mark("has_exists")
for is_expr in where.find_all(exp.Is):
if getattr(is_expr, "negated", False): mark("has_is_not_null")
else: mark("has_is_null")
# ── JOIN
for join in tree.find_all(exp.Join):
mark("has_join")
kind = (join.args.get("kind") or "").upper()
if kind == "INNER": mark("has_inner_join")
elif kind == "LEFT": mark("has_left_join")
elif kind == "RIGHT": mark("has_right_join")
elif kind == "FULL": mark("has_full_join")
elif kind == "CROSS": mark("has_cross_join")
elif kind == "SEMI": mark("has_semi_join")
elif kind == "ANTI": mark("has_anti_join")
# ── ORDER
order = tree.find(exp.Order)
if order:
mark("has_order_by")
for o in order.expressions or []:
if o.args.get("desc"): mark("has_order_desc")
else: mark("has_order_asc")
if tree.find(exp.Limit): mark("has_limit")
# ── FUNC
scalar_date_funcs = {"date", "datediff", "strftime", "date_add", "date_sub"}
scalar_string_funcs = {"substr", "substring", "upper", "lower", "length"}
for func in tree.find_all(exp.Func):
fname = func.name.lower()
mark("has_scalar_func")
if fname in scalar_date_funcs: mark("has_date_func")
if fname in scalar_string_funcs: mark("has_string_func")
if fname in {"concat", "concat_ws"}: mark("has_concat")
if fname == "cast": mark("has_cast")
if fname == "coalesce": mark("has_coalesce")
if fname == "rank": mark("has_rank")
if fname == "row_number": mark("has_row_number")
if fname.startswith("json_") or isinstance(func, (exp.JSONExtract, exp.JSONExtractScalar)):
mark("has_json_extract")
if tree.find(exp.Array): mark("has_array_construct")
if tree.find(exp.Unnest): mark("has_unnest")
if tree.find(exp.When): mark("has_case_when")
# Else 추정: Case + Not When만 있는 경우
if tree.find(exp.Case) and not tree.find(exp.When):
mark("has_case_else_guess")
if tree.find(exp.Interval): mark("has_interval")
# ── Expression-level operators
if tree.find(exp.EQ): mark("has_eq")
if tree.find(exp.NEQ): mark("has_neq")
if tree.find(exp.GT) or tree.find(exp.LT): mark("has_gt_lt")
for node in tree.walk():
if isinstance(node, (exp.Add, exp.Sub, exp.Mul, exp.Div, exp.Mod)):
mark("has_arith_expr")
break
return vec
이 정도로 구분해놓고, 일단 실험 돌려보자. 더 최적화하기가 빡시당

※ NL2SQL / Agent 관련해서 읽어보면 좋은 LINK
https://github.com/yhyu/agentic-text2sql
GitHub - yhyu/agentic-text2sql: Agentic RAG for open domain text-to-query
Agentic RAG for open domain text-to-query. Contribute to yhyu/agentic-text2sql development by creating an account on GitHub.
github.com
Waii.ai: Enterprise Text-to-SQL API | Accurate SQL Generation
Postgres, Trino, MySQL, Databricks, Snowflake, SQLServer, BigQuery, Athena, Presto, Redshift, Oracle, MongoDB, SQLite and OSQuery. We are constantly adding more. If you don't see your database here, check in with us and see when it will be available.
www.waii.ai
'Data Science > Research' 카테고리의 다른 글
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[4] (0) | 2025.09.04 |
|---|---|
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[3] (2) | 2025.08.18 |
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[1] (4) | 2025.08.04 |
| SQL2NL 모델 실험진행(2) (3) | 2025.07.21 |
| SQL2NL 모델 실험진행 (1) | 2025.07.15 |