https://eglife.tistory.com/360
SQL2NL 모델 실험진행
https://eglife.tistory.com/359 SQL2NL 모델 개선방안에 대한 검토 - Prompt & RAGhttps://eglife.tistory.com/358 연구주제 고찰(2)MCP를 많이 파봤지만, 일단 연구주제는 SQL2NL이 위주였으면 한다는 교수님의 바람이 있
eglife.tistory.com
이제 진짜 실험진행 + Data를 뽑아볼 때가 왔다.

실험의 관건은 SQLGlot이 얼마나 유의미한가..를 따져보는 것이다.
기존 BIRD Data set 1534ea에서 DB용 1434ea, test용 100ea를 분류해서 실험을 진행한다.
아 댕짜증나는게 실험 하기도 전에 Module 끼리 버전 맞추는 것만 해도 한 세월이다.
미추어버리겠다 진짜.. 그냥 이런거 자동으로 맞춰주는 놈 있으면 좋겠다.
우여곡절끝에 라이브러리 / 모듈 패키지를 설치했다. 결론은, 어떤 New 실험 세팅을 할 때는 그냥 Python 가상환경을 Setting하라는 것이다. 그냥 Base Python 돌리면 旣 깔아 놓은 모듈들끼리 충돌이 있어서 ERROR 잡는데만 한 세월이다.
이것 때문에 GPT랑 겁나게 싸웠음..
각설하고,
완벽하진 않지만 그래도 내가 하고 싶었던 실험의 결과를 일부 이끌어냈다.
일단, 연구제목은 "Structure-Aware Prompting for SQL-to-NL"
최초 예고한데로, SQL to NL Task의 정확도를 향상시키기 위한 연구를 진행하였고, 이전 KCC 때 Schema Linking을 통해 정확도를 올렸던 것의 추가버전이다.
내가 생각하는 Research의 Flow는 다음과 같다.(NL2SQL 분야 연구내용을 벤치마크!)
| 1. SQL2NL Schema Linking 유효성 확인 KCC 完 2. SQL2NL Few-shot 유효성 확인 中 - 어떤 기준으로 Few-shot을 선택할 지에 대해서 Novelty 中 ------ Future Work -------- 3. SQL2NL VectorDB + RAG 적합성 확인 - SQL<->NL Pair Data를 어떤 기준으로 Vector Embedding 할 까? : Novelty 4. SQL2NL Model Fine-tuning 기법 검토 Finally : SQL2NL Model 만들고 배포 |
위 Flow에서 현재 1번은 KCC논문연구로 확인했고, 이번 K-DS로 2번을 확인중인데 실험결과 다행히?(사실 당연하긴 하지만;;) 유효성을 확인할 수 있었다.
실험은 드넓은 Text2SQL 분야에서 일단 BIRD에만 집중을 하기로 했다. KCC에 사용했던 BIRD Dev Data 약 1500ea 중에 1400ea를 Standard로 정하고 여기에 겹치지 않는 Data 100ea를 Test data로 설정해서 SQL2NL 실험을 진행했다.
평가지표론, BERT(Recall) , BART, BLEU를 사용했다.
실험은 Llama LLM Base로
| 1. Zero-shot(Naive) : 그냥 Llama에 SQL2NL Promt만 던진 것 2. Random fewshot : Standard data 중 random으로 fewshot 제공(여기선 5ea Example 제공) 3. Structure based fewshot(ours) : Standard data 중 SQLGlot - diff 함수 기준, Input SQL과 유사한놈들을 추려서 fewshot제공(5ea) |
요렇게 진행했다.
저 3번이 나의 Novelty고, SQL의 AST기반 유사도 비교 알고리즘을 이용한 것이며 SQLGlot Open source로 공유된 것이다.
논문에는 이 알고리즘에 대한 설명도 자세히 적어야 할 것이다.
실험결과를 Rough하게 정리하자면 아래와 같다. Llama 8b / 70b 모두 실험을 진행했는데 결과추세는 비슷하니까 8b만 적어보자면,
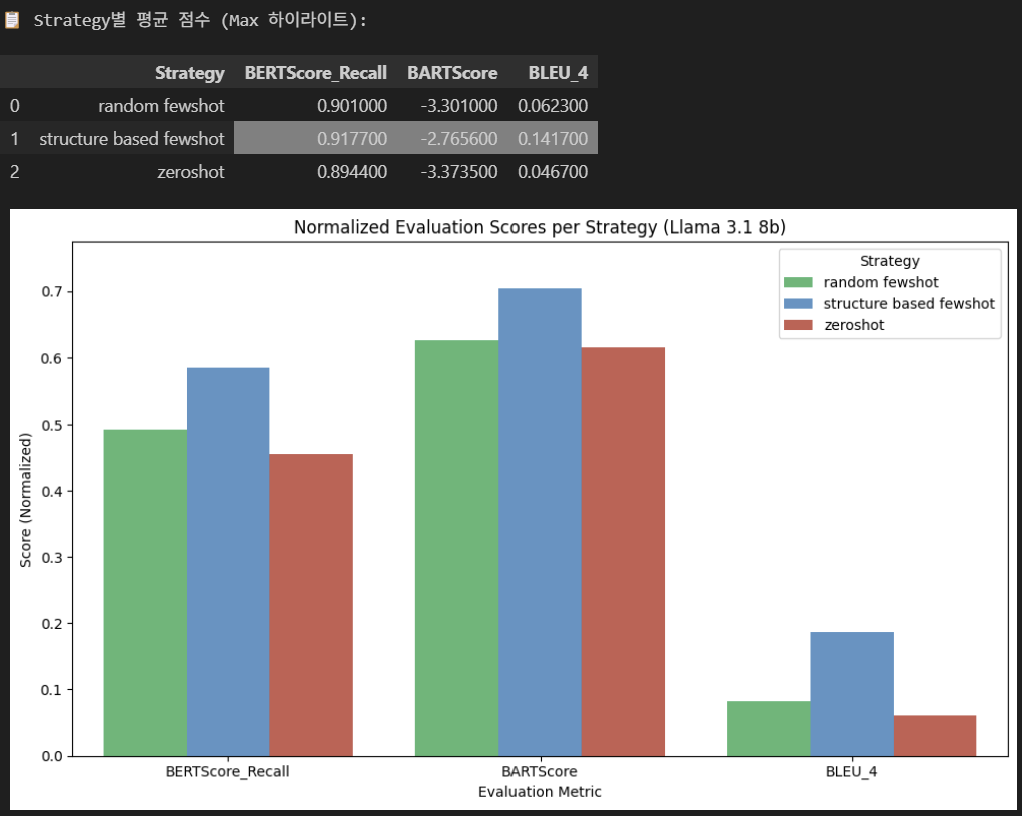
일단, 실험 Graph는 저걸로 뽕깔진거 뽑아보고 논문 Draft를 작성해보자.
논문 구성은 KCC를 벤치마크하자. 채움이 필요한 부분은 아래와 같을 것이다.
| 0. Abstract ( A.K.A. 요약 ) 1. 서론 2. 이론소개 - Prompt Engineering이 뭔지, Fewshot이 뭔지, SQLGlot이 뭔지, AST기반 유사도비교 알고리즘이 뭔지, Evaluation Matrix 각 각에 대한 소개 3. 실험 3.1 실험환경 3.2 실험결과 분석 4. 결론 및 향후 연구 5. 참고문헌 |
0, 1번은 그냥 내가 생각했던 분야니까 지금껏 블로그에 정리했듯이 수려하게 적으면 될 거 같고 2번 이론소개 부분을 적절히 잘 정리해서 표현할 필요가 있다. 특히 Bold처리한 부분에 그림까지 넣어서 잘 소개해야 겠다.
3번도 적절히 적으면 될 거 같은데 실험결과이다보니 표 / 그래프를 잘 구성해야 겠다. 4번은 내 연구 Flow에서 Future Work에 대한 부분을 넣으면 되고 5번은 지금까지 Print하고, 읽어보고, 따로 Local에 저장해두었던 Paper들 정리해서 나열하면 될 거 같다.
Abstract
| Structured Query Language (SQL) is the standard language used for managing and querying relational databases. While considerable research has been devoted to converting natural language into SQL (NL-to-SQL), the reverse task has received relatively lower attention. However, SQL-to-NL models hold significant potential like developer-assistance tools and as reference generators for evaluating NL-to-SQL systems. In this paper, we explore the use of large language models (LLMs) for the SQL-to-NL conversion task and propose a structure-aware prompting strategy to improve semantic accuracy in generated outputs. By retrieving structurally similar SQL queries from a labeled dataset and providing them as few-shot examples, our method effectively guides the LLM toward more faithful and contextually appropriate natural language descriptions. Experiment results demonstrate that our method improves SQL-to-NL accuracy on BIRD datasets based on Evaluation matrix including BERT Recall, BART, BLEU_4 score. |
요 정도면 잘 요약한 거 같다. 항상 영어로 쓸 때는 뭔가 좀 불안하다. 한글이면 표현이 어색한 지 아닌 지 바로 알 수 있는데 ㅠㅠ 이럴 때 영어공부를 아무리 많이 했어도, Native가 아닌게 확 체감이 된다.
일단 금번 연구는 여기까지 마무리를 지어본다.

'Data Science > Research' 카테고리의 다른 글
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[2] (6) | 2025.08.11 |
|---|---|
| SQL2NL 모델 추가 실험(VectorDB, Embedding)[1] (4) | 2025.08.04 |
| SQL2NL 모델 실험진행 (1) | 2025.07.15 |
| SQL2NL 모델 개선방안에 대한 검토 - Prompt & RAG (2) | 2025.07.10 |
| 연구주제 고찰(2) (3) | 2025.07.08 |