Review 10 - 각종 Tree / Graph Traversals in Python
https://eglife.tistory.com/78 Review 9 - Queues & Stackshttps://eglife.tistory.com/77 Review 8 - Python Data Structurehttps://eglife.tistory.com/75 Review 7 - Python Algorithm design & Testing & Debugginghttps://eglife.tistory.com/74 Review 6 - Python
eglife.tistory.com
대망의 파이썬 마지막부분이다. 아 정말 쉽지 않은 여정이다.
Graph vs Tree :
a. Graph는 Cycle 있어도 OK. Path 상 같은 Node 2개 있는 case
b. Graph는 Island가 있을 수 있다. 다른 Node들과 동 떨어진 Node들의 모음이 있는 case
나중에 알고리즘 부분에 Graph Traversal이 또 인사를 한다. 본 Blog C++ 영역에서 이 부분은 또 Review가 되어있을 예정!
( Hint, Shorted Path / All Path Shortest Path etc. )
1. Data Indexed Arrays
Dictionary와 Set 배울 때 나왔던 개념. 특정 element를 Search할 때, Hash 기능을 써서 one shot one kill로 data를 탐색할 수 있다고 했다. O(N) -> O(1)


Data indexed array에선, array의 index 에 값을 넣고, 그 값이 존재 하냐 안 하냐만 T/F로 value에 넣는다.
즉, 만약 이 세상에 Data가 0~11밖에 없다고 가정했을 때,
di_array = set() 이라는 set 구조를 선언하면, set은 0~11까지 메모리를 잡아 먹고 각 칸의 값이 모두 False인 Array일 것이다. 여기서 2, 9를 add하면 2, 9에 해당하는 element만 False에서 True로 바뀐다.

이렇게 하면 2라는 data, 9라는 data를 찾을 때 바로 2, 9의 T를 보고 확인하던가, 3의 F를 보고 없다는 걸 확인할 수 있어서 Search에 O(1)이 걸리는 것에 환호를 했고 Data를 index로 삼는 것에 환호를 했지만...
이 세상의 모든 data가 0~11일리는 없다.
그러면 일단 English의 경우도 data를 index로 삼을 수 있을까?
a,b,c,,,,z는 26개니까 각 영어단어를 27진수로 바꾸면 English도 Unique integer로 치환이 가능하다.
그러나.. 이 세상 문자는 영어소문자만 있는 게 아니고 ASCII코드만 봐도 255가 있다. 그러면 256진수를 사용해야 하는 것인가,,?
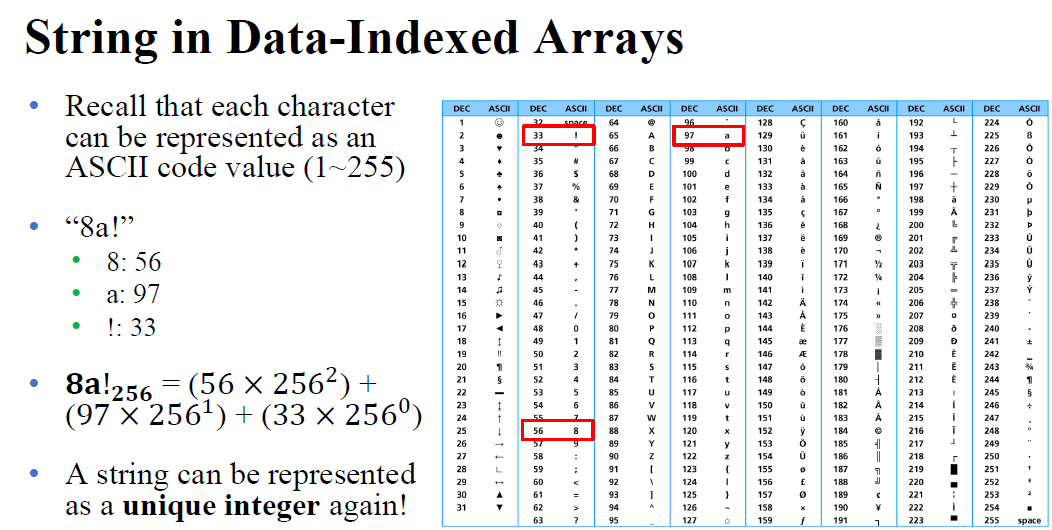
하지만 컴퓨터가 처리할 수 있는 integers, memory는 제한적이다. finite 하다!
Python은 따로 제한을 두진 않지만, C/C++/Java에선 처리 가능한 최대 integer를 2^32 - 1로 제한을 해두었다.
그래서 이 숫자 안쪽에서 계산이 돌아가야 맞다.
그래서 #Hash 라는 테크닉을 쓰는 것인데.. 여기도 Collision이 발생한다.

"ace!" , "pace!" 처럼 겹치는 놈들은 Linked list처럼 주렁주렁 매달아서 보관하자는 의견이 나왔다.
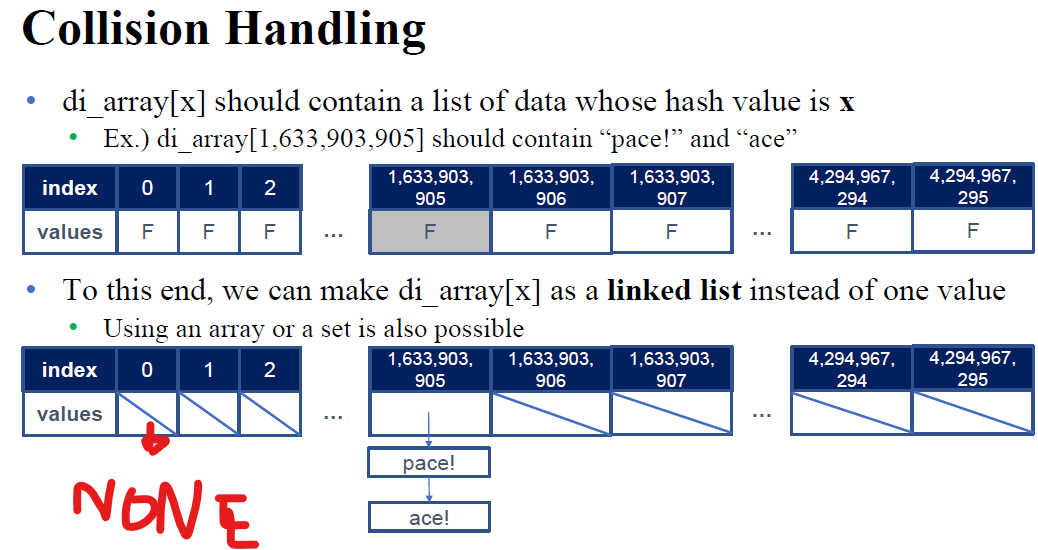
좀 기괴한 아이디어긴 하지만, 일단 이 의견으로 코드 짜는 것은 충분히 가능하다.

"ace!" 라는 놈이 A에 있는지 찾으려면, 일단 "ace!"라는 친구의 hash_value를 구하고,
그 hash_value에 해당하는 Node를 방문한 뒤 거기에 달려있는 Single Linked List를 하나씩 탐색해보면 된다.
2. Hash

Data indexd array와는 좀 다른게, 일단 Data를 Hash function을 통해 hash value를 구하고, 더 숫자를 제한하고 싶으면 reduction까지 이용해 적절한 index에 Linked list로 더해가는 작업이 수행된다.
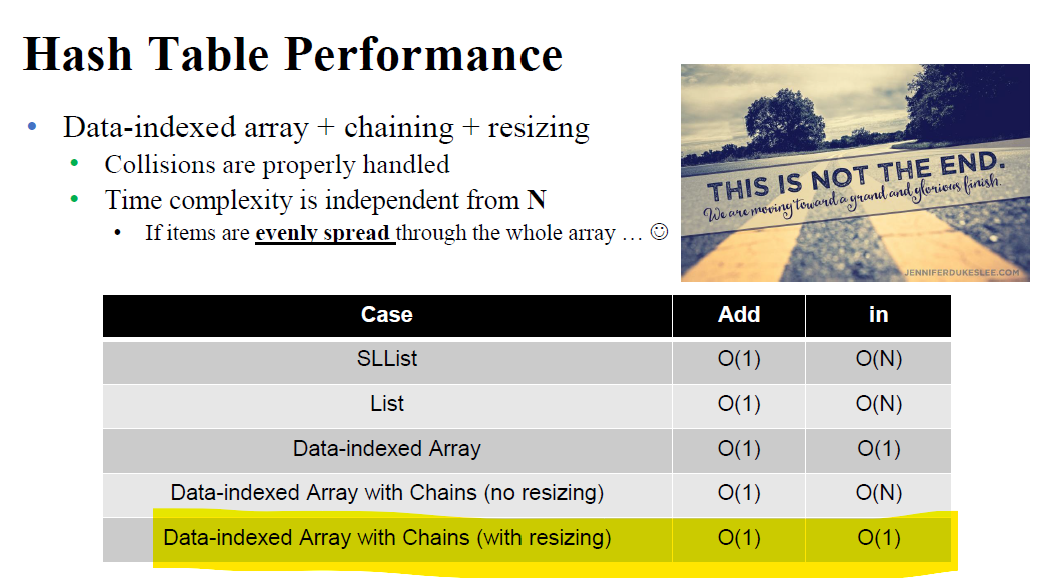
즉, 제한된 index안에 data들을 적절히 우겨넣는? 개념이라고 보면 된다. (Data indexed Array는 좀 더 Naive하다. 그냥 일렬로 쭉 펴서 T / F로만 구분하는 것이니..))

위 표에서 "in"은 Search를 의미하는데, Data-indexed Array with Chains -> Hash Table은 갑자기 in 에서 Chain의 길이인 K가 등장했다.
만약 Hash Table의 Indices 가 M개이고, 우리의 Item이 N개 이면, K = N/M이다.(균등하게 분포되어있다고 가정)
그러면 문제점이.. Search Time이 O(K) -> O(N/M) 인데, 이건 Big O 관점에서 그냥 O(N)이라 이점이 없다.
그래서 결론은 M이 Fixed Value면 무조건 O(N)이니까, 우리는 M값을 건드려야 한다.( => Need Resizing )

이런식으로 N/M이 1.5 이상 되려고 할 때마다 M을 2배씩 키워주면 N/M이 1.5를 넘지 않게 된다.

근데 이게, N/M이 커져서 M의 resizing이 되면, 그 순간 indices가 늘어나면 기존에 넣었던 Chained data들을 싸그리 다시 Arrange 해야한다.
뭔가 냄새가 난다.. Resizing도 따지고 보면 비싼 작업이라 찜찜할 따름..

Resizing은 할 때마다, 현재까지 Data의 개수가 N개라면 O(N)의 시간이 소요된다. 그래서 결국 다시 도찐개찐.. 으로 볼 수도 있겠으나 희소식은 우리가 Resizing을 매번 하느 ㄴ것이 아니라는 것이다.
즉, 한 번 Resize할 때 indices를 2배 때려주기 때문에 N개의 Element를 추가할 때 총 Resizing 2N-1 이라 N으로 나눠주면 결국 Big O는 O(1)이다. (이게 맞나..? 등비수열의 합이 저게 맞는 진 잘 모르겠다.)
( 아 맞네, 8까지 더하면 2^r -1 에 의해 2^4-1 = 15 인데, 이건 2N-1 => 2*8-1 이다. )
또 고려해봐야 할 것이, Element들이 Hash Table에 균등하게 분포하도록 Hash Function을 잘 Design해야 한다.
 |
 |
좌측의 Hash function들은 나름의 아이디어를 냈지만 Rebundant 한 한계점이 분명히 보인다.
(그래도 아래로 갈수록 Hash Table 內 Data 쏠림 현상은 줄일 수 있을 거다)
결국 도입된게, 우측처럼 "B" 진수를 사용하자는 것

B를 256이라는 걸 써버리면, 256^4는 Max Interger라서 끝 4자리만 같으면 모든 String을 같은 Hash Table Node에 넣어버린다.
그래서 User가 예측하기 어렵게 prime number ( 소수 ) 를 bas 로 삼는다.
그치만 이 이상은.. 너무 어려운 개념이라 이상의 내용은 GPT내용을 첨부하고, SKIP...
|
해시 테이블에서 소수(Prime Number)를 사용하는 이유와 그 사용 방식을 설명하겠습니다.
이유:
사용 방식:해시 테이블에서 소수를 사용하는 방식은 다음과 같습니다:
|
정리 : Data indexed array가 있고, 이걸로 표현하면 add / search 모두 O(N)이지만 Max integer 한계로 data간 collision이 발생하며, 이를 예방하기 위해 Chain을 사용했는데 Chain을 사용할 때도 index 개수가 고정이면 Search의 Big(O)가 O(N)이라서 N: data개수, M : index개수 -> N/M이 특정 값보다 커질 때마다 M을 2배씩 키우는 Resizing 작업을 해서 Search의 Big(O)를 다시 O(1)으로 만든다. 하지만 이 때도 Data가 Hash Table에 균등하게 퍼져있지 않으면 Search에서 O(1)을 보장할 수 없어서 Hash Function을 적절히 잘 Design해서 element들의 Hash value가 균등하게 퍼지게 해야하는데, 이 때 Hash function엔 소수(Prime number)를 진수의 base로 삼아 element들 간의 collision은 줄이면서, 최대한 even하게 hash table 내에서 element들이 분포될 수 있도록 한다.
[※ sh-256 같은 function들을 검색해보면 좀 더 자세한 hash function 내부구조를 알 수 있다.
이걸로 Python 기초내용 복습 끄읕!
- E. O. D -

'SW 만학도 > Python' 카테고리의 다른 글
| Tree BFS / DFS(Pre/In/Post Order) 구현 in Python & C (0) | 2025.02.13 |
|---|---|
| Review 10 - 각종 Tree / Graph Traversals in Python (0) | 2024.07.09 |
| Review 9 - Queues & Stacks (0) | 2024.07.08 |
| Review 8 - Python Data Structure (1) | 2024.07.08 |
| Review 7 - Python Algorithm design & Testing & Debugging (0) | 2024.07.07 |