Review 5 - Python OOP(Objected Oriented Programming)
https://eglife.tistory.com/68 Review 4 - Python File I/Ohttps://eglife.tistory.com/67 Review 3 - Loop & Set,Tuple,Dictionaries,Mutabilityhttps://eglife.tistory.com/66 Review 2 - Python의 기본 Module , Classhttps://eglife.tistory.com/65 Review 1 - Py
eglife.tistory.com
머리 박고 달리자~
이번엔 파이썬 Search다. 이 이후로 내용이 째끔 머리 복잡할듯 헌데 일단 달려보자
우리가 공부해볼 알고리즘은 Search, Sort 요 2개의 내부 구현은 어떻게 되는 지 알아보자.
(사실 Python에선 Sort가 다 알아서 해주긴 한다만.. 원리를 공부해보는 것도 의미가 있을듯)
1. Linear Search - Algorithm
민망하지만 전체 Data를 싹 돌면서 Target Value를 찾는 것 ㅎ;;
Target Value를 찾으면 고놈의 index를 Return한다.
Target Value가 여러 개라면? 가장 첫 번째로 나타난 놈을 return. 없으면 -1 return.

이렇게 그림으로, NLP로 Logical하게 설명할 수 있는 것이 알고리즘의 영역이다.
이제는 이 알고리즘을 Implementation을 하기 위해 코딩이 필요하다.
방법 1. while문
def linear_search(lst:list,value:int) -> int :
i = 0
while True :
if lst[i] == value :
return i
# break 필요 없다
if i == len(lst)-1 :
return -1
i += 1
방법 2. While with Sentinel
target value search를 위해 while문을 돌 때마다 계속 len(List)보다 작은 지 체크하는 것이 시간소모가 있으니 그것을 방지해보고자 한다.
찾고자 하는 list의 맨 끝에 target value를 Sentinel이라는 녀석으로 추가하자 -> 이러면 Search는 일단 fail이 나진 않는다.

장점은 Search 속도는 빠르지만, 단점으로 원본 List를 조작하는 것이 위험부담이 따른다.
lst = [4,-5,1]
sentinel add
def linear_search_sentinel(L:list,value:any) -> int:
lst.append(value) # sentinel add
i = 0
while(lst[i] != value) :
i += 1
lst.pop() # sentinel 제거
if(i == len(lst)) : return -1
else : return i
linear_search_sentinel(lst,1)
2
-
linear_search_sentinel(lst,-1)
-1
방법 3. 제일 무난한 for loop
lst = [4,-5,1,123]
def linear_search_for(L:list,value:any) -> int :
for i in range(len(L)):
if L[i] == value:
return i
return -1
print(linear_search_for(lst,123))
print(linear_search_for(lst,124))
3
-1
※ Linear Search 의 Time Complexity 를 개산해보자

import time
lst = [4,-5,1,123]
def linear_search_for(L:list,value:any) -> int :
for i in range(len(L)):
if L[i] == value:
return i
return -1
t_start = time.perf_counter()
print(linear_search_for(lst,123))
t_end = time.perf_counter()
print("시간소요(ms):",(t_end - t_start)*1000) #ms 단위
t_start = time.perf_counter()
print(linear_search_for(lst,124))
t_end = time.perf_counter()
print("시간소요(ms):",(t_end - t_start)*1000) #ms 단위
3
시간소요(ms): 0.2395000192336738
-1
시간소요(ms): 0.027300033252686262
희한하게도 target을 찾지 못했을 때가 시간이 덜 걸린다;;
위 방식들의 Time complexity는 아래와 같다.( 10M data 기준으로 체크했을 때, while:느리고 sentinel 중간, for loop 이 빠르다)

target이 처음 , 중간, 끝 부분에 있는 것의 소요시간을 보면 Linear 한 것을 볼 수 있다.
Time Complexity는 len(L)에 비례한다.
만약에 List의 값이 ascending하게 Sorting이 되어 있다면?
2. Binary Search ( List가 Sorting이 되어있다고 가정하자! )
반 쪼개서 검증할 때마다 후보군의 반(Half)씩 날리는 접근법이다.

lst = [-5,0,5,7,10,11,13,14,77,80,1234,10000,123123123]
def binary_search(L:list,value:any) -> int :
start = 0
end = len(L)-1
while end >= start :
idx = (end+start)//2
if L[idx] < value :
start = idx + 1
else :
end = idx -1
if start < len(L) and L[start]==value :return start
else:
return -1
binary_search(lst,80)
9
Binary Search는 C로 구현된 Python의 Built in function에 버금 가는 서치 속도를 가지고 있다.

Binary Search는 속도가 엄청 빠르지만 log(len(L)), Sorting하는 게 시간이 오래 걸리는 단점이 있다.
3. Selection Sort
Why sort? Binary Search의 경우 Sorting이 되어 있어야 쓴다. 그 외에 Sorting은 그냥 기본적으로 필요하지요
어떤 List가 있을 때, left : Sorted 영억 / right : Unsorted 영역 이라고 했을 때, unsorted에서 제일 작은 Minimum 값을 제일 왼쪽 친구랑 Swap을 하라.
이제 그 맨 왼쪽 친구는 변동일 필요 없다. -> Sorted 영역으로 입성
그리고 다신 Unsorted 영역에서 젤 작은 값을 맨 왼쪽으로.. 위 과정 반복
#내가 그냥 해본 것 selection sort를 recursive 하게
lst = [100,-1,0,23,777,-123,9,-3,4,-1234,12]
start = 0
def sel(L:list,start:int) -> None :
if start == len(L)-1 : return
idx = L.index(min(L[start:]))
L[start], L[idx] = L[idx], L[start]
start += 1
sel(L,start)
sel(lst,0)
lst
[-1234, -123, -3, -1, 0, 4, 9, 12, 23, 100, 777]
흠.. 좀 조잡하지만 되긴 된다.
일단 기초적으로 for문 부터 다시 한 번 보자.
lst2 = [100,-1,0,23,777,-123,9,-3,4,-1234,12]
def sel2(L:list)->None:
for i in range(len(L)) :
smallest = i
for j in range(i+1,len(L)):
if L[j] < L[smallest] :
smallest = j
L[i], L[smallest] = L[smallest], L[i] #일단 최소값 찾고 swap은 1번
---------------------
sel2(lst2)
lst2
[-1234, -123, -3, -1, 0, 4, 9, 12, 23, 100, 777]
요 Selection Sort의 Time Complexity 는 어떻게 될까?
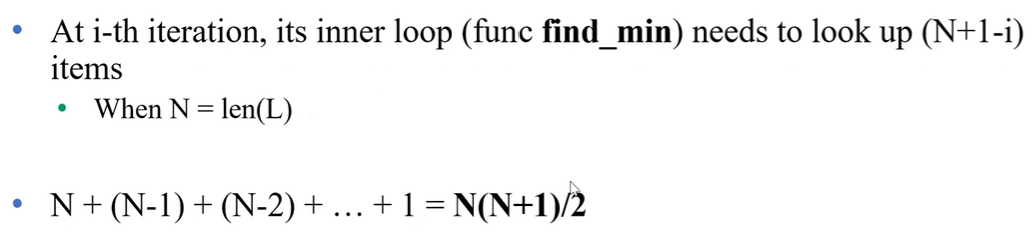
Linear Search는 N에 비례, Binary Search 는 log N 에 비례..
그치만 지금 이 Selection Sort는 N^2 이다. 생각해보면, 지금 Sorting 하는 과정에서 Min 값을 " Search" 하는 작업이 많이 들어가서 어쩔 수 없다.
4. Insertion Sort
Selection Sort는 약간 Basic 하다. 직관적이고..
그래서 약간 다른 느낌으로 Sorting을 해보자. 과연 어떤 아이디어일까..??
참고로, Selection은 Unsorted에서 시간 소모가 크고, Insertion은 Sorted 영역에서 시간소모가 크다.
일단 Unsorted list의 leftmost를 target으로 잡고( 시간이 이 때는 소요가 안 됨 ㅎㅎ 간단한 작업이라.. )
, sorted 영역의 어느 부분에 넣을지 고민을 해야한다.( 여기서 시간 소모 多 )
그리고 적절한 영역을 찾았으면 그 부분에 Insert!

lst2 = [100,-1,0,23,777,-123,9,-3,4,-1234,12]
def ins(L:list) -> None :
for i in range(len(L)):
for j in range(i,0,-1):
if(L[j] < L[j-1]):
L[j],L[j-1] = L[j-1],L[j]
else : break
ins(lst2)
lst2
[-1234, -123, -3, -1, 0, 4, 9, 12, 23, 100, 777]
Selection Sort와 달리 Insertion Sort에선 Swap이 많이 발생한다.
이거 때문에 사실 Insert/Selection Sort의 TIme Compelxity는 비슷하다. ~N^2

하지만, 만약에 list가 거의 Sorting이 되어있는 상태면 Insertion sort가 유리하다.
왜냐면, 많이 sort 되어 있으면 대부분의 for문에서 swap을 안 하고 넘어가기 때문이지요
이 때는 그냥 ~ kN 이라서 O(N) 으로 많이 시간이 절약된다.
5. Big O
Program 개발에 쓰이는 기회비용 2가지

- Measure Time Complexity
Time module 갖고 직접 젠다? : 장점 - 측정 쉽고, 정확한 시간 측정 가능 / 단점 - 측정시간이 너무 오래 걸린다. 그리고 다른 Factor에 의해 시간 측정값이 변할 수 있다.
그래서 코드만 보고도 대충 감을 잡기 위해 N 을 이용해 계산한다. 장점 - 알고리즘의 Scalability를 파악할 수 있다. 단점은 측정하기 귀찮(?)고 실제 시간은 아니고 예측값이다.
-> 이걸 간소화해서 Big O Notation을 사용해보자. (N이 굉장히 굉장히 클 때를 가정해서 생각하자)

Asymptotic ( 점근적 ) 분석을 해보자. N이 무지무지 큰 경우를 생각한다.
규칙 1 . 가장 최악의 경우만 고려한다.
규칙 2 . Operation 중에 Order of Growth가 가장 큰 경우만을 생각한다.
규칙 3. Highest Order만 남기고 나머지 지운다.
규칙 4. 상수를 지운다.
예시 )

Big O 에선 지수함수가 엄청나게 강력하다. 그래서 지수함수에 붙은 N은 없애지 말자. 앞에 곱해진 N, 지수에 있는 2N 모두 그대로 보존!
- E. O. D -

'SW 만학도 > Python' 카테고리의 다른 글
| Review 7 - Python Algorithm design & Testing & Debugging (0) | 2024.07.07 |
|---|---|
| Review 6 - Python Recursion & Merge Sort (0) | 2024.07.07 |
| Review 5 - Python OOP(Objected Oriented Programming) (0) | 2024.07.05 |
| Review 4 - Python File I/O (0) | 2024.07.02 |
| Review 3 - Loop & Set,Tuple,Dictionaries,Mutability (2) | 2024.07.02 |