Review 3 - Loop & Set,Tuple,Dictionaries,Mutability
https://eglife.tistory.com/66 Review 2 - Python의 기본 Module , Classhttps://eglife.tistory.com/65 Review 1 - Python programming basics프로그래밍은 안 쓰다 보면 까먹는다. 더군다나 전공자가 아니면 정말 1~2주만 정신 놓
eglife.tistory.com

이번엔 Python으로 File I/O (input / Output) 하는 것을 Review해보려고 한다.
file에서 input을 받아오고(read), 파이썬으로 작업한 것들 file에 output으로 write 하는 법을 알자!
music, ppt, image 등.. 뭐 많은 종류의 파일이 있지만 basic 하게 text file위주로 알아보자
1. File Open
file = open("file_example.txt","r") #open 이라는 함수를 실행
# file을 열어서 python이 file을 다룰 때 쓰는 특정 object형태로 저장
contents = file.read()
file.close()
print(contents)
first line of text
2 line of text
3 line of text
Open이라는 것을 통해 file_name ( 실제는 file 저장위치까지 포함해서 써야함 ) 과 mode를 설정해 python 만의 file을 다루는 object를 만들고 file에 assign 한다.
file mode에는 r,w,a가 있는데 주의할 점은 w 모드는 기존 내용을 싹 다 지우고 백지부터 시작하는 것이라, 단순 추가 수정만 할 거면 'a' mode로 파일을 열어야 한다.
file.read()의 경우 파일의 맨 첫부분을 가리키고 있는 cursor가 맨 뒤까지 쭉 가는 동안 모든 text들을 string type으로 저장시키는 것이고, 실제로 contents 라는 것은 file 내부 모든 text가 string으로 저장된 형태이다.
끝으로, file을 마지막으로 close를 해야 Memory 관리를 효율적으로 할 수 있다.
# 자동으로 file close까지 해준다.
with open("file_example.txt","r") as f:
content = f.read()
print(content)
first line of text
2 line of text
3 line of text
보통 file을 열 때는 위와 같이 "with" statement를 쓴다.
이러면 구문이 끝날 때 자동으로 file.close() 까지 되는 것이다.
2. File Path

Mac 은 " / " 로 file path를 구분하고, Windows 는 " | (백슬래시) " 로 path를 구분하는데 파이썬에선 그냥 " / " 로 통일한다.
../ --> 요거는 상위 폴더로 가는 거네. 유용할 듯하다.
# 대충 이렇게 앞에 r 붙치면 file path 덕지 덕지 더러워도 잘 읽는다.
with open(r"C:\Users\Python/untitled.txt","r") as f2:
contents2 = f2.read()
print(contents2)
--------------
asdf
12 3 4
5
3. 좀 더 세밀한 File read
with open("file_example.txt","r") as f :
c = f.read(10) #10글자만 읽고, cursor는 11번째 Character 앞에서 깜빡중
print(c)
---------------띄쓰 포함
first line
한 번 지나간 cursor는 다시 돌아오지 않으니, 지나간 것을 다시 읽고 싶으면 파일을 다시 열어야 한다.

with open("file_example.txt","r") as f :
c = f.readlines()
print(c)
['first line of text\n', '2 line of text\n', '3 line of text']for i in range(len(c)):
c[i] = c[i].strip()
c
['first line of text', '2 line of text', '3 line of text']# readline을 이용하면 한 줄 씩 읽는 것이 가능하다. 이 때 한 줄 읽고나면 커서는 다음 줄을 가르킨다.
with open("file_example.txt","r") as f :
c = f.readline()
c2 = f.readline()
print(c)
print(c2)
first line of text
2 line of text
for loop을 이용하면, readline을 이용하지 않고도 라인을 하나 하나씩 다룰 수 있다.
# for문 돌려보기
with open("file_example.txt","r") as f2 :
for x2 in f2:
print(x2)
first line of text
2 line of text
3 line of text
x
-----------------------------
with open("file_example.txt","r") as f2 :
x = f2.read()
print(x)
first line of text
2 line of text
3 line of text
HDD 말고 인터넷에 있는 파일도 읽을 수 있다. by url 주소!
# 이런식으로 module을 하나 import 해줘야한다.
import urllib.request
url = "https://robjhyndman.com/tsdldata/ecology1/hopedale.dat"
with urllib.request.urlopen(url) as f:
for x in f:
x=x.strip()
x = x.decode("utf-8")
print(x)
urllib.request.urlopen을 통해 url에 있는 파일을 열어서 f 라는 이름에 file object를 저장해달라는 것
모든 line 마다 x.strip()으로 빈 칸을 지운다.
x.decode("utf-8") 의 경우 인터넷에서 긁어온 파일에 한하여 써주는 것이다.
인터넷에서 긁어온 파일이 txt가 아니고, 음악이나 사진일 수도 있으니 일단 Python은 파일을 'Byte" type으로 가져온다. 그리고 user가 txt file을 읽어온 것이라 txt로 변환이 필요할 시 알아서 decode를 통해 해당 파일을 변환시키는 시스템이다.
관련해선 아래 내용 참고


Bit 는 Binary Type의 약자로 0,1 로 이루어진 최소 단위이다. 근데 이건 너무 작으니까 컴퓨터는 1Byte = 8Bit 을 적용하여 Byte 단위로 움직인다.
4. Write Mode
w - mode = 백지화 후 새로 입력, 커서가 기존 내용 다 지워지고 맨 첫번째로 이동한다.
a - mode = 기존내용에 추가적으로 입력한다는 것만 주의하자.

※ 파일을 두 가지 모드로 동시에 열어서 작업하는 것도 가능하다.
아래 예시를 참고하면 되고, in/out file이 햇갈리지 않게 코드를 짜야 하겠다. 당연하겠지만..ㅎㅎ
with open("file_example.txt","r") as inf,open("output_test.txt","w") as outf :
contents = inf.read()
outf.write(contents)
with open("output_test.txt","r") as r:
c = r.read()
print(c)
---------------
실화냐?
실화냐고!
5. File I / O Reading Techniques
어떤 text가 아래와 같다고 해보자, 이렇게 정제되지 않은 data들을 전처리할 줄 알아야 한다.
Marc 2024-1234 A
Jane 2023-1243 B+
Chris 2022-1032 A
우리의 목표는 이 Text에서 이름/학번/성적을 각 각 따로 list에 만들어 저장하는 것
1) while 문을 활용해서 line을 하나 하나 read 한다.
2) strip 으로 항상 line 별로 양 옆 \n 을 지워준다.
3) split을 통해 적절히 String을 쪼개서 list 형태로 만들어 준다.
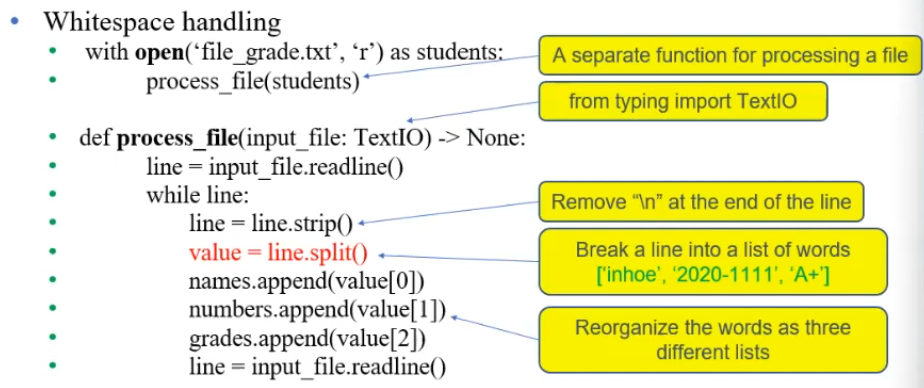
# 요런 식으로~
from typing import TextIO
names,numbers,grades = [],[],[]
def processing_file(input_file : TextIO) -> None :
line = input_file.readline()
while line:
line = line.strip() # 양 옆에 enter 지우기
value = line.split(" ")
names.append(value[0])
numbers.append(value[1])
grades.append(value[2])
line = input_file.readline()
with open("example.txt","r") as students:
processing_file(students)
print(names,numbers,grades)
type(names)
['Marc', 'Jane', 'Chris'] ['2024-1234', '2023-1243', '2022-1032'] ['A', 'B+', 'A']
list
실제 이거 보다 좀 더 복잡한 file의 경우 전처리를 어떻게 할까나?
파일 앞 부분에 필요 없는 Data가 붙어 있는 경우 이 놈들을 한 번에 제거가 필요할 때!
# DIRTY PART1
# DIRTY PART2
Marc 2024-1234 A
Jane 2023-1243 B+
Chris 2022-1032 A
이 때, Header 부분을 없애줘야 한다.
어라? #으로 시작하네? 이렇게 규칙을 찾아서 없애주면 된다. ( 이 예시의 경우 그렇단 말이다 )
# 이번엔 startswith으로 걸러주면 된다.
from typing import TextIO
names,numbers,grades = [],[],[]
def skip_header(input_file : TextIO) -> str:
line = input_file.readline()
line = line.strip()
while line.startswith("#"):
line = input_file.readline()
line = line.strip()
return line
def processing_file(input_file : TextIO) -> None :
line = skip_header(input_file)
while line:
line = line.strip() # 양 옆에 enter 지우기
value = line.split(" ")
names.append(value[0])
numbers.append(value[1])
grades.append(value[2])
line = input_file.readline()
with open("example.txt","r") as students:
processing_file(students)
print(names,numbers,grades)
type(names)
['Marc', 'Jane', 'Chris'] ['2024-1234', '2023-1243', '2022-1032'] ['A', 'B+', 'A']
list
이렇게 상황에 맞게 data를 preprocessing 할 수 있는 능력을 키워야 한다.
그렇지만 만약!

이렇게 skip_header 에서 line을 return 하지 않는 다면,
skip_header의 while문을 탈출 할 때, cursor가 이미 정상 line을 가르키고 있는데 process_file 에서 다시 readline을 하며 정상적인 line 하나를 건너 뛰게 된다.
이런 edge case들들 조심해야 한다.
이번엔 좀 더 더러운 Case를 알아보자~~
# DIRTY PART1
# DIRTY PART 2
Marc 2024-1234 A
-
Jane 2023-1243 B+
-
Chris 2022-1032 A
이렇게 중간에 Data가 빵꾸가 나 있는 경우가 있다.
from typing import TextIO
names,numbers,grades = [],[],[]
def skip_header(input_file : TextIO) -> str:
line = input_file.readline()
line = line.strip()
while line.startswith("#"):
line = input_file.readline()
line = line.strip()
return line
def processing_file(input_file : TextIO) -> None :
line = skip_header(input_file)
while line:
line = line.strip() # 양 옆에 enter 지우기
if line != "-":
value = line.split(" ")
names.append(value[0])
numbers.append(value[1])
grades.append(value[2])
line = input_file.readline()
with open("example.txt","r") as students:
processing_file(students)
print(names,numbers,grades)
['Marc', 'Jane', 'Chris'] ['2024-1234', '2023-1243', '2022-1032'] ['A', 'B+', 'A']
Error 가 "-" 때문이라는 걸 정확히 알고 있기에 가능한 솔루션인데,
실제로 더 복잡한 case가 있을 땐 어떻게 처리해야 하는 지.. 그건 알아서 할 수 있어야 한다.
- E. O. D -

'SW 만학도 > Python' 카테고리의 다른 글
| Review 6 - Python Search(Linear / Binary) & Sort(Selection / Insertion) (1) | 2024.07.05 |
|---|---|
| Review 5 - Python OOP(Objected Oriented Programming) (0) | 2024.07.05 |
| Review 3 - Loop & Set,Tuple,Dictionaries,Mutability (2) | 2024.07.02 |
| Review 2 - Python의 기본 Module , Class (0) | 2024.07.01 |
| Review 1 - Python programming basics (1) | 2024.07.01 |