3. C++ Standard Library (3)
https://eglife.tistory.com/35 2. C++ Standard Library (2) https://eglife.tistory.com/34 1. C++ Standard Library (1) 아 ~ 이게 무슨 영어, 중국어 배우는 것도 아니고 코딩하나 하는데도 프로그래밍 언어가 너무 많다;; 이거
eglife.tistory.com

이번 시간엔 어렵고 복잡스러워서 피하고 싶지만..
중요하기 그지 없는 C++의 Call by Reference에 대해 공부를 해보자.
어렵지만, 한 번만 제대로 개념을 잡아 놓으면 여러모로 편리할 것으로 기대한다.
그 전에 복습 잠깐!

- Vector의 경우 vec[0] 처럼 index 0에 해당하는 값을 쉽게 Update하여 수정할 수 있다.
- 저장된 값을 읽을 때도 vec[0] , ver[1] 처럼 index 활용해서 읽는 것이 가능하다. Python list와 유사

- C++에서 list에 있는 값을 추가 / 삭제 --> push_front/back, pop_front/back 으로 가능하다.
- Iterator의 경우, 최초 begin()으로 initialize를 한 뒤, advance로 특정 값을 가리키게 했다면 insert를 통해 그 값 앞 뒤로 다른 value가 들어와도 원래 가르키던 value를 포인팅한다.
- 만약에 erase를 통해 iterator가 가르키던 값을 삭제하면 iterator는 이제 전혀 이상한 값을 가르키게 된다.
본격적으로 금일의 공부 시작
Default Arguments in Functions
#include <iostream>
int divide ( int a, int b = 2){
int r = a / b ;
return r;
}
int main(){
std::cout << divide(12) << std::endl;
//6 --> default값 발동
std::cout << divide(12,3) << std::endl;
//4
return 0;
}
- 함수를 선언할 때, 위에 int b = 2 처럼 default 값을 설정해주면, Parameter가 적게 들어왔을 때 알아서 default 값을 써서 계산해준다.
Call by Value
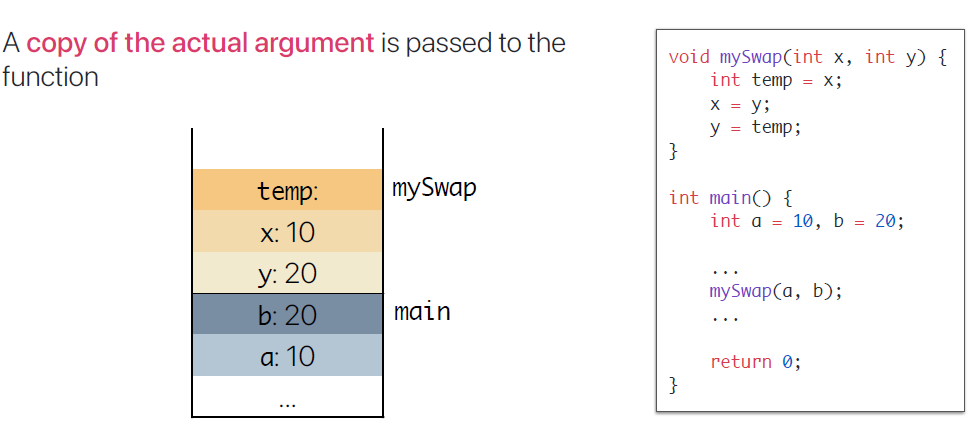
- Call by Value의 대표적인 예시다. a, b 값이 값만 mySwap 함수 내부에 x, y에 복사되기 때문에 a,b 값은 전혀 영향을 받지 않는다.
Call by Reference - Using Pointers
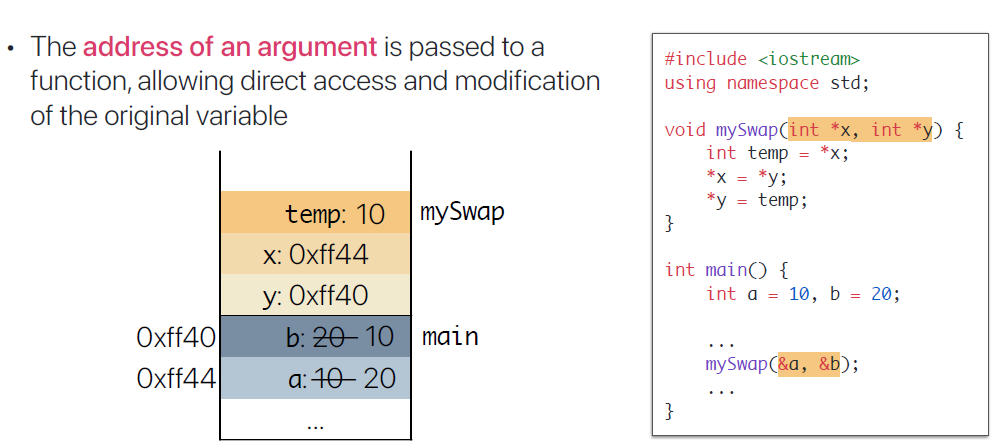
- Call by Reference를 Pointer를 통해 구현하는 대표적인 예시다. mySwap 함수의 int *x 를 통해 pointer x는 어떤 int value를 저장중인 메모리의 주소를 가르킨다는 것이고, * 표시는 *x로 call 되었을 때 x에 저장된 주소를 따라가 그곳에 저장되어 있는 int 값을 반환한다는 것이다. ( * 표시 --> Dereference )
- 따라서 int *x --> int 값을 저장중인 메모리의 주소를 반환해야 하므로 main 함수에선 int a와 int b variable이 저장되어 있는 메모리의 주소를 의미하는 --> &a , &b를 적어줘야 한다.
Call by Reference - Reference Parameter
- C++에만 존재하는 C++의 꽃과 같은 Call by Ref 방법이다.
#include <iostream>
void swap(int & x, int & y){
int temp = x;
x = y;
y = temp;
}
int main()
{
int a = 5;
int b = 11;
std::cout << "Before swap a:" << a <<"\t" << "b:" << b << std::endl;
swap(a,b);
std::cout << "After swap a:" << a << "\t" << "b:" << b << std::endl;
return 0;
}
// Before swap a:5 b:11
// After swap a:11 b:5
- 함수에 data type & variable_name --> 이런식으로 표현하면 자동으로 call by reference이다. Main 함수에서 함수를 call 할 때에도 인자로 주소값 &을 넣지 않고 그냥 variable을 넣으면 된다.
- Reference ( = alias ) 는 pointer "처럼" 동적하지만 compiler 상황마다 동작하는 게 달라서 명확히 설명하긴 어렵다.
- 그냥 C++ 안에서 pointer "처럼" 내부동작 한다는 것으로 이해하면 될듯
- 하지만 Reference Parameter의 단점은 위 예시의 경우, 실수로 Ref Parameter x,y를 바꿔버리면 main에서도 a,b가 바뀌어 버리는 일이 발생한다.
Const Reference
void maswap(const int & x, const int & y){
int temp = x;
x = y;
y = temp;
} // ERROR
- 이렇게 함수에 const data_type & variable_name 으로 선언하면, 함수 내에서 variable 값에 변동이 생기려고 하는 순간 Compile 시 Error가 발생한다.
- 즉, const로 묶어놓은 Reference Variable에 대해선 Call by Reference로 값이 변동될 리가 없다.
Reference Return
- C++에선 Function이 value에 대한 reference를 반환하게 할 수도 있다.
#include <iostream>
#include <map>
#include <string>
int& middle(std::map<std::string,int>& m){ //함수 OUTPUT이 Reference
int index = m.size() / 2;
auto it = m.begin();
for(int i=0;i<index;i++){
it++;
}
return it->second;
}
int main()
{
std::map<std::string,int> m = {
{"a",1},
{"b",2},
{"c",3}
};
middle(m) = 100;
for(auto& p : m){
std::cout << p.first << ": " << p.second << std::endl;
}
// a: 1
// b: 100
// c: 3
return 0;
}
- 이렇게 되면 코드 중간에 middle(m) 처럼, map에 있는 value를 바꿀 수도 있다. 왜냐하면 함수 middle이 map value의 주소를 반환하고 있기 때문이다.
- Reference Return은 불필요한 Copy를 줄여 large data를 처리할 때 효율적이다.
- 그리고 이를 통해 Origin Data를 함수의 returned reference를 통해 바로바로 수정처리 할 수 있다.
- cin 의 chain rule도 ( cin >> var1 >> var2 ; ) 이런 Reference parameter를 이용해서 가능한 구조이다.
Function Overloading
- C++에선 C와 다르게 함수 이름이 같아도 된다. 다른 data type의 parameter를 받는다면!

- C++에선 Compiler가 함수에 입력된 data의 개수, type등으로 같은 이름의 함수 중에 어느 것을 특정할 지 알아서 선택해준다. ( 유용한 기능! )
- 그렇지만 위의 예시 기준으로, 여전히 같은 기능을 갖는 함수를 3번이나 만들어줘야 하는(이름이 같더라도..) 불편함이 있다. 그 불편함을 Handling 하기 위해서 아래와 같이 Function Templates 기능을 이용할 수 있다는 것!!
Function Templates
- Function template은 fucntion이 아무 Data type이 입력되어도 동작될 수 있게 해준다.
- template은 <> 를 이용해 아래와 같이 사용해준다.
template <typename T>
void myswap(T &a, T &y)
{
T temp = x;
x = y;
y = temp;
}
- 사용법! 함수 선언은 하나 해줬는데, 다양한 data type의 variable을 넣어줘도 제대로 동작하는 것 확인
#include <iostream>
#include <map>
#include <string>
template <typename T>
void myswap(T &x, T &y)
{
T temp = x;
x = y;
y = temp;
}
int main()
{
int a = 1;
int b = 2;
myswap(a,b);
std::cout << a << "\t" << b << std::endl;
double c= 1.5;
double d = 2.5;
myswap(c,d);
std::cout << c << "\t" << d << std::endl;
std::string e = "ABC";
std::string f = "DEF";
myswap(e,f);
std::cout << e << "\t" << f << std::endl;
// 2 1
// 2.5 1.5
// DEF ABC
return 0;
}
- 만약, 여기서 실수를 방지하기 위해 myswap함수에 무조건 int 변수만 들어가게 하고 싶다면 myswap<int>(a,b); 이런식으로 꺽쇠표시를 해주면 된다.
- template <typename T> 에서 T는 아무 문자를 사용해도 무방하다.

- 위와 같이 template type을 명확히 알 수 없는 경우엔 data type을 명확히 구분해줘야 한다.
- 그리고 myswap<int> , myswap<double>과 같이 템플릿이 사용된 함수가 따로 따로 지정되면 copiler는 각 함수에 대한 코드를 따로 분리해서 관리한다.
- 만약에 function template에 서로 다른 두 종류의 argument가 들어가면 어떻게 될까?
#include <iostream>
#include <string>
template <typename T1, typename T2>
void fprint(T1 x, T2 y)
{
std::cout << x << "\t" << y << std::endl;
}
int main()
{
fprint("ABCD",1.5);
fprint<std::string,int>("STR",9); //type specify
// ABCD 1.5
// STR 9
return 0;
}
- 위와 같이 Template 선언해 줄때 type을 각각 따로 만들어주면 된다.
// data type을 명시해줬는데 다른 거 넣으면 어떻게든 int로 반환한다.
// double data -> int로 출력! int 자리에 str 넣으면? Compile ERROR!
fprint<std::string,int>("STR",true); //type specify
// ABCD 1.5
// STR 1

Memory Management
- Dynamic memory allocation은 프로그램이 runtime에 memory를 할당할 수 있게 해준다.
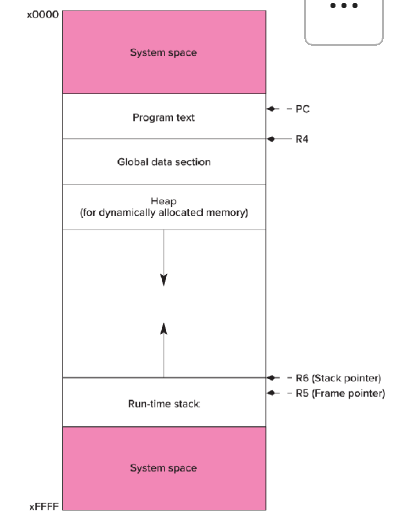
Heap vs Stack
- Heap : Dynamic allocation을 위한 메모리이다. 특정 manual 대로 할당되거나, smart pointer를 통해서 사용 가능하다.
(Heap --> ex) 사용자에게 data를 받을 때, vector/list 등 data 할당에 따라 memory가 늘었다 줄었다 하는 구조 )
- Stack : Static allocation을 위해 자동으로 할당되는 구조이다. 주로 function call이나 local variable들을 저장한다.
- Dynamic allocation(동적할당) --> compile time에 정확히 파악 안 되는 메모리 구조에 사용하기 좋다.
Dynamic Memory Allocation

- C에서는 메모리 할당 후, 그것을 활용해 이것 저것 동작을 취한 뒤에 free로 메모리를 날려준다.
- C++에서는 new 를 통해 C의 malloc 처럼 heap에 메모리를 할당해주고, delete[]로 memory를 free 시켜준다.
- 메모리할당에 실패할 시, try - catch 구조로 error를 처리해준다.
int main()
{
int *array;
int n;
std::cin >> n;
try{
array = new int[n]; // malloc(n*sizeof(int))
delete[] array;
}catch(const std::bad_alloc& e){
std::cerr<<"FAILED: "<<e.what()<<std::endl;
return 0; //e.what() --> Error 이유 출력
}
return 0;
}
- 아니면 아래와 같이 nothrow를 이용해서 error를 대응하는 방법도 있다.
#include <iostream>
int main()
{
int *array;
int n;
std::cin >> n;
array = new (std::nothrow) int[n];
// array에 memory가 할당되지 않아도 exception이 아니라 nullPtr을 반환하라
if(array == nullptr){
std::cerr<<"Failed"<<std::endl;
return 0;
}
delete[] array;
return 0;
}
- new :
1. runtime에 Memory를 할당한다.
2. Single object : Type *ptr = new Type; --> 여기서 Type은 int, string 등 data type 이름
3. Array : Type * array = new Type[n]; --> n은 몇개의 칸을 할당할 지 정해달라는 것
- delete 방법 (C에선 free) :
1. Single object : delete ptr;
2. Array : delete[] array; --> [ ] 대괄호 필수!
Access to dynamic memory
- 만약 class라는 object를 동적할당으로 new를 통해 만들었고, 그 안에 element인 member를 Call하고 싶으면 아래 2가지 방법이 있다.
1. (*ptr).member
2. ptr -> member
- 아래는 포인터를 이용해 vector에 element를 넣고, 읽는 방법 (*vec)[ ] 을 이용하면 cout을 통해 쉽게 내용물 출력이 가능하다.(Dereference)
#include <iostream>
#include <vector>
int main()
{
std::vector<int>* vec =
new std::vector<int>(); //argument가 필요하면 괄호 안에 추가하면 된다.
vec -> push_back(10);
vec -> push_back(20);
std::cout << "1st: "<<(*vec)[0]<<
" and 2nd: " << (*vec)[1] << std::endl;
// 1st: 10 and 2nd: 20
return 0;
}#include <iostream>
#include <vector>
int main()
{
std::vector<int>* vec =
new std::vector<int>(); //argument가 필요하면 괄호 안에 추가하면 된다.
vec -> push_back(10);
vec -> push_back(20);
std::cout << "1st: "<<(*vec)[0]<<
" and 2nd: " << (*vec)[1] << std::endl;
// 1st: 10 and 2nd: 20
std::cout <<"Case1: ";
for(int elem : *vec)
{
std::cout << elem << "\t";
}
std::cout<<std::endl;
std::cout <<"Case2: ";
for(std::vector<int>::iterator it = vec->begin();it!=vec->end();it++) //지금 vec이 pointer로 되어 있으니까 화살표로 표시
{
std::cout<<*it << "\t" ;
}
// Case1: 10 20
// Case2: 10 20
delete vec; //memory 삭제
return 0;
}Smart Pointers
- pointer를 쓰고 나서 release를 안 하여 memory leak가 생기는 것을 방지하고자 Smart Pointer를 쓰기도 한다.
Smart Pointers - Unique Pointer
- Data type 설정이 필요하다.
- 하나의 unique pointer는 무조건 하나의 변수를 가르키고, 다른 변수에 copy가 불가하다.
- Pointer가 scope에서 벗어나면 자동적으로 Memory를 Release 해준다.
#include <iostream>
#include <vector>
#include <memory>
int main()
{
std::unique_ptr<std::vector<int>>vecPtr(new std::vector<int>()); //constructor 만들어 줌
vecPtr -> push_back(10);
vecPtr -> push_back(20);
(*vecPtr)[0] = 30;
for(auto item : *vecPtr){
std::cout << item << std::endl;
}
// scope 종료되면 자동으로 memory release
return 0;
}
// 30
// 20
Smart Pointers - shared_ptr
- std::unique_ptr과 유사하다
- 다중 변수에 share 해서 포인터지정이 가능하다.
- copy , assigned 될 수 있다.
#include <iostream>
#include <vector>
#include <memory>
int main()
{
std::shared_ptr<std::vector<int>>vecptr1(new std::vector<int>);
std::shared_ptr<std::vector<int>>vecptr2=vecptr1;
// shared ptr
// std::shared_ptr<std::vector<int>>vecptr2(new std::vector<int>);
vecptr1 -> push_back(1);
vecptr2 -> push_back(23);
for(auto elem : *vecptr1){
std::cout << elem << std::endl;
}
for(auto elem : *vecptr2){
std::cout << elem << std::endl;
}
// 1
// 23
// 1
// 23
return 0;
}
- 위와 같이 shared_ptr은 한 놈만 데이터를 수정해줘도 같이 엮여 있는 다른 ptr도 값이 변한다.

아으 진짜 포인터쪽 내용도 겁나리 많은 C++
내용 이해는 쉬운데, 코딩문제를 풀어보려고 하면 넘나 어렵다.
필기 공부는 앵간치 했으니까 이제 머리 박고 실습문제를 쭉 풀어봐야겠다.
어차피 실습문제 풀다보면 개념공부도 다시 해야할 수도ㅋㅋ...
얼른 부딪쳐보자 실습에~ ㅠㅠㅠㅠ

'SW 만학도 > C++' 카테고리의 다른 글
| 6. Out_of_class Definition & Operator Overloading (0) | 2024.04.10 |
|---|---|
| 5. Classes (0) | 2024.04.09 |
| 3. C++ Standard Library (3) (1) | 2024.03.24 |
| 2. C++ Standard Library (2) (1) | 2024.03.22 |
| 1. C++ Standard Library (1) (0) | 2024.03.21 |